Optimizing throughput for async RL
What I learned serving DeepSeek-V4-Flash as an RL rollout engine on 2 DGX Spark machines.
Code for this recipe lives in inference-recipes/inference.
This series is my attempt to make the work on my 2 DGX Spark machines reusable. Each post will include the scripts, configs, failures and systems reasons behind the choices.
Could I serve a 284B-parameter MoE as an RL rollout engine on 2 desktop machines, without cloud compute, and still learn something that carries to production serving?
That question starts with RL post-training. The model has to write its own training data, usually called rollouts.A rollout is one generated training sample. In agentic RL, it can also mean a longer trajectory with tool calls, retrieval steps and multiple model turns. It samples those rollouts token by token, and that sampling is usually the slowest part of the loop.
Recent open-weight RL systems hide some of that wait with asynchronous generation.Asynchronous generation means the sampler keeps producing rollouts while training continues. The learner may train on slightly stale samples, but the hardware spends less time idle. Luke Huang’s survey of frontier async RL maps that pattern.
The next question is serving speed. Can you make each decoded token cheaper without changing what the model samples? Speculative decoding is the tool for that.Speculative decoding uses a smaller draft model to propose tokens, then asks the main model to verify them. Correctly implemented rejection sampling preserves the main model’s output distribution.
When DeepSeek-V4-Flash and DeepSpec landed, I wanted to see how far I could push the setup. The narrow question was throughput. The broader question was which small-hardware serving lessons still matter when you scale up.
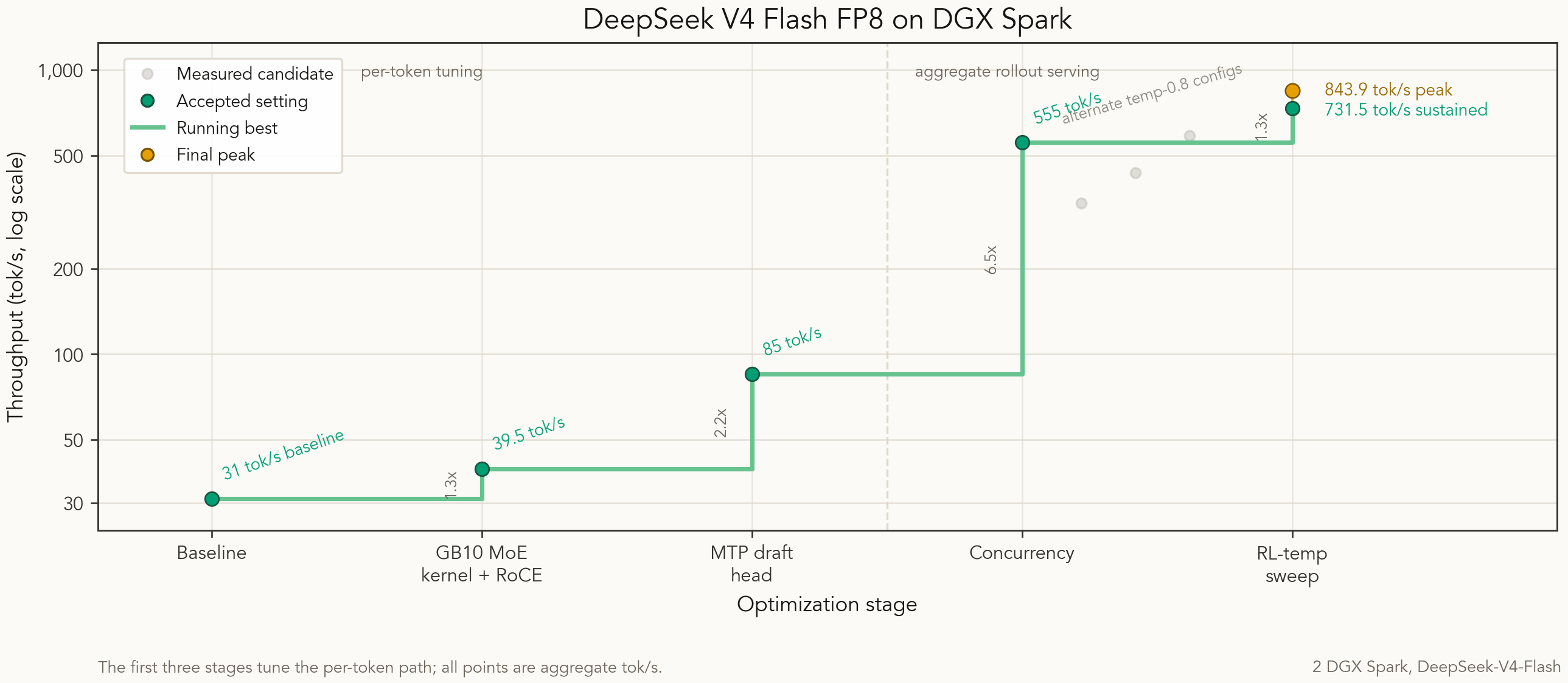
Figure 1. Aggregate throughput after each accepted serving setting. The first 3 stages tune the per-token path. The last 2 tune the rollout engine at concurrency. Every point is aggregate tok/s.
- Why rollout throughput is the bottleneck
- What this builds on
- About this series
- Thinking about hardware
- The serving levers
- Concurrency and the speculative-decoding surprise
- The recipe
- What changes when the trainer is live
- Reproduce this for a new model
- What this shows
Why rollout throughput is the bottleneck
Start with the loop. In RL post-training, the model generates its own training data. It samples a batch of responses. A verifier scores them. Then a gradient step updates the policy.
Generation is the slow part. On reasoning and agentic workloads, it is often the largest cost in the loop.
Agentic RL makes this worse. A long task can call the model many times across tool use, retrieval and web steps. A single trajectory can run to tens of thousands of decoded tokens.
Every one of those tokens is paid at generation speed. The longer the task, the more the run waits on the sampler.
So you want generation to be faster. The catch is that many speedups change what the model learns. In RL, the policy learns from its own samples. If you distort those samples, you distort the gradient.
If you think of RL progress as a product, it decomposes into:
learning speed = effectiveness × throughput
Effectiveness is how much learning signal you get from each rollout. Throughput is how much rollout and training work the system does per unit time.
Most speedups buy throughput by spending effectiveness. Asynchronous execution trains on slightly stale policy samples. Off-policy replay reuses old trajectories. Lower-precision rollouts shift the sampling distribution. Each one trades some learning quality for speed.
Speculative decoding is the exception. A small draft model proposes tokens. The large target model checks them. A rejection step throws out any token the target would not have produced.
With exact rejection sampling, the accepted tokens follow the target model’s distribution. That makes speculative decoding the first speedup to try, before anything that changes the rollout distribution.
Throughput is a systems problem. On fixed compute, it is the only term left to move. Faster throughput means faster learning.
So the question is concrete. Compute is fixed at 2 DGX Spark, with 128 GB of unified memory each. How many rollout tokens per second can I get from DeepSeek-V4-Flash on that hardware, at the temperature I would actually train at?
What this builds on
DeepSpec is DeepSeek’s codebase for training and evaluating draft models for speculative decoding. DeepSeek released it on 26 June 2026. It packages 3 draft algorithms, DSpark, DFlash and Eagle3.
This recipe is the serving side of the same idea. I use DeepSeek-V4-Flash’s native multi-token-prediction layer as a draft head inside the model. That is the design direction DeepSpec studies with DSpark.
The framing above comes from NVIDIA’s NeMo-RL speculative-decoding report. It measures speculative decoding for RL rollouts on datacenter Blackwell. It credits the throughput decomposition to earlier work by Piché and colleagues.
I measure the same idea on consumer Blackwell, the GB10 in DGX Spark. One result comes out the opposite way.
About this series
This is the first recipe in the series. Each recipe gives you a config you can copy and the reasoning behind it.
This one covers inference. The next covers ProRL and an async RL engine for small-model training on the same hardware.
Thinking about hardware
One constraint shapes every choice in this recipe. On this hardware, generation speed is set by memory bandwidth, not compute.
Once you see that, the serving levers below read as consequences rather than tricks.
Each DGX Spark has:
- a GB10 chip, NVIDIA’s consumer-class Blackwell
- 128 GB of unified memory, about 119 GB usable for serving
- 273 GB/s of memory bandwidth
- a 200 GbE RoCE link to the other machine
Every decode step reads the model weights from memory. On GB10, that read is the expensive part.
If you decode one token, you pay the full read for one token. If you batch 256 sequences, one weight read serves 256 next-token decisions.
That reduces the problem to one question. How many tokens can you place behind each weight read before something breaks?
This is the memory-bound side of the roofline model.A roofline model asks what limits performance first, moving data or doing math. Here the limit is moving weights from memory, not running the arithmetic. Below a critical batch size, the chip sits idle waiting for weights. Adding more concurrent work is close to free.
You leave that regime only when you pack enough tokens behind each read to saturate compute. On GB10 with a model this size, you never get close. The machine stays memory-bound across the useful range. That is why aggregate throughput is the number that moves.
That also explains the single-stream ceiling. At batch 1, you pay a full weight read per token. Decode tops out in the tens of tokens per second.
My best single-stream config for DeepSeek-V4-Flash reached 38.3 tokens per second. You cannot beat that per stream. You can only stack more streams behind each read.
Unified memory adds the second rule. The CPU and GPU share one 128 GB pool, with no separate video memory. Weights, KV cacheThe KV cache stores attention keys and values from earlier tokens. It lets the model avoid recomputing the whole prompt on every new token, but it grows with sequence count and context length. and activations all draw from it.
Every extra sequence costs KV cache. KV cache competes with the weights for the same space. Concurrency is not free. You buy it from memory headroom.
The 2 machines are not optional. DeepSeek-V4-Flash is 149 GB across 46 shards. It does not fit in one machine’s 119 GB.
I split the weights across both machines with tensor parallelism of 2.Tensor parallelism splits one model across multiple devices. Each device holds part of the weights, and the devices exchange activations while generating each token. Each machine holds about 75 GB of weights, which leaves room for KV cache.
Once you split the model, the network becomes part of every token. Each decoded token triggers a cross-machine exchange. The link between the 2 machines matters as much as the chips. Moving that link from a plain network socket to RoCE is one of the largest wins in the sequence.
One more fact explains the first failure. GB10 is consumer-class Blackwell, compute capability SM121. The Blackwell in a datacenter B200 is SM100.
A low-precision checkpoint is not portable between them by default. Its kernels are compiled for a specific tensor-core path. GB10 has less shared memory. It lacks the datacenter tensor-core instructions. It is also missing an instruction for converting to 4-bit floats.
So a checkpoint quantized for datacenter Blackwell can refuse to run here. I treat that as a compatibility check before optimization.
Last, the model. DeepSeek-V4-Flash is a 284B-parameter mixture-of-experts model.A mixture-of-experts model has many expert networks but routes each token through only a few of them. That keeps active compute lower than the total parameter count suggests. Only about 13B parameters are active for each token.
Each token routes to 6 of 256 experts plus 1 shared expert. That means each token reads about 13B of the 284B weights. This is why decode lands in the tens of tokens per second rather than far lower.
The model also ships one multi-token-prediction layer, a small draft head.A multi-token-prediction head tries to predict future tokens beyond the immediate next token. That makes it useful as an internal draft model for speculative decoding. I use that head for speculative decoding later.
The serving levers
Table 1. Throughput after each serving lever on 2 DGX Spark. Single-stream throughput measures the per-token path at low concurrency. Aggregate throughput measures concurrent rollout serving. The first row is the first configuration that served, so the 31 to 843.9 change is an end-to-end rollout-server improvement, not a tuned-baseline speedup.
| Lever | Measured configuration | Single-stream (tok/s) | Aggregate (tok/s) |
|---|---|---|---|
| Fit the model across both machines | native FP8/FP4 checkpoint, TP=2, default MoE kernel, TCP transport | 12.6 | 31 |
| Use the GB10 MoE kernel and RoCE transport | B12X MoE kernel, NCCL over RoCE | 18.7 | 39.5 |
| Use the model’s draft head | MTP-1 speculative decoding | 33.4 | 85 |
| Fill the batch with rollout work | concurrency 128, greedy decoding | - | 555 |
| Re-test at RL sampling temperature | concurrency 256, temperature 0.8, MTP-1 | - | 843.9 peak / 731.5 sustained |
The table has 2 regimes. The first 3 rows tune the per-token path. The last 2 rows tune the rollout engine. That split matters because single-stream speed and aggregate throughput answer different questions.
Single-stream speed tells you how fast one sequence advances. Aggregate throughput tells you how much training data the server produces per second. RL cares about the second number once you have enough parallel rollouts.
Fit the model with tensor parallelism
The next question is how to fit 149 GB into 119 GB. You cannot, on one machine.
Tensor parallelism solves that by splitting one model across devices. Each machine holds a shard of the weights. During generation, the machines exchange activations and partial results so the sharded model behaves like one model.
In vLLM, I run this as a 2-node job with --tensor-parallel-size 2 and --nnodes 2.vLLM recommends tensor parallelism when a model does not fit on one GPU or one node. Multi-node tensor parallelism needs fast communication because the workers exchange data during each forward pass. One Spark runs the API server. The other runs headless as the worker. Each machine holds about 75 GB of weights.
This is the first config that ran. It served at 12.6 tokens per second single-stream, 31 aggregate. That is the floor. Everything after makes the same model faster without touching a weight.
Make the MoE kernel match the chip
The model serves, and it is slow. Which part is slow?
The expert matrix multiplications are the expensive part. A mixture-of-experts layer first routes tokens to experts, then runs the expert matmuls, then gathers the outputs. That route-pack-compute-gather path is where kernel engineering matters.
vLLM picks its MoE kernel automatically. On GB10 it picked MARLIN, a general fallback. The serving image also has a GB10-specific B12X path. One environment variable switches it on, VLLM_USE_B12X_MOE=1.
B12X does not change the model. It changes the low-level GPU program that runs the experts. Same weights, same math, different execution path.
On a new chip, check the kernel choice before you tune higher-level settings. Auto-selection optimizes for “runs everywhere,” not “fast here.”
B12X alone did not show the full gain because tensor parallelism made the network part of every token. Over a TCP socket, the faster expert kernel waited on communication.
Move cross-node traffic onto RoCE
A faster expert kernel barely moved aggregate throughput. Why?
At tensor parallelism of 2, every decoded token crosses the network. The 2 machines exchange activations on every step. A token cannot finish until that exchange finishes.
My traffic first ran over a plain TCP socket. A faster kernel does not help if its tokens wait on a slow link.
The 2 machines have a 200 GbE RoCE link for this.RoCE is RDMA over Converged Ethernet. NCCL is NVIDIA’s communication library for multi-GPU and multi-node jobs. NCCL can use that RDMA transport instead of falling back to a TCP socket.
On GB10, GPU Direct RDMA Disabled in the logs is expected.GPUDirect-RDMA lets a network adapter access GPU memory directly on systems that support it. GB10 can still benefit from RoCE transport even when GPUDirect-RDMA is disabled. The win is the RoCE transport path, not GPUDirect-RDMA.
B12X and RoCE together took the pair from 31 to 39.5 aggregate. RoCE is the largest infrastructure win in the per-token path.
RoCE inside a container needs each RDMA device passed with --device, plus --cap-add=IPC_LOCK. I started with a bind-mount of /dev/infiniband. It looks right. The devices appear inside the container.
Docker’s device cgroup still blocks the process from opening them.A device cgroup controls which host devices a container process may open. A bind mount can show the files without granting permission to use them. NCCL falls back to TCP. The logs can look healthy because the model still generates.
You have erased the win with no serving error. Read the NCCL log and confirm it reports the RoCE HCA, not No device found. A clean GB10 run can still print GPU Direct RDMA Disabled. That line is not the failure.
Use the model’s draft head
Now the model fits, the expert kernel matches the chip and the cross-node link is on RoCE. The remaining per-token question is speculative decoding.
DeepSeek-V4-Flash has one multi-token-prediction layer built in. I use it as the draft head. With speculative decoding on, that head proposes future tokens. The main model verifies them in one pass.
Accepted tokens are nearly free. Rejected ones still cost a verify. The question is how many tokens the draft head should propose.
I swept k, the number of proposed tokens, over 1, 2 and 3. One MTP layer means accuracy falls off fast down the sequence. The first proposed token is accepted about 79% of the time, the second 48%, the third 16%.
That decay sets the choice. k=2 wins single-stream latency, because a second accepted token shortens one sequence’s path.
k=1 wins aggregate. Under concurrency, every proposed token competes for a batch slot. A token that lands 16% of the time wastes that slot. k=3 and up lose everywhere.
An RL rollout engine is an aggregate-throughput problem, so k=1 wins.
MTP-1 took single-stream to 33.4 tokens per second. MTP-2 set the single-stream best at 38.3. Aggregate at low concurrency reached 85. The per-token path is now about as good as it gets. The rest is concurrency.
Concurrency and the speculative-decoding surprise
Raise concurrency to the wall
Once the per-token path is tuned, the next lever is concurrency. The question is how many sequences the machines can hold before something breaks.
Each added sequence shares the same weight read. Aggregate throughput rises as more rollout work sits behind each read.
Two settings mattered. I set --max-num-batched-tokens 8192, because the speculative-decoding default of 2048 starves the batch. I set --gpu-memory-utilization 0.9 to give KV cache room.
I served at 128k context, not the model’s full 1M. That choice left memory for more concurrent sequences.
The wall is a kernel limit, not memory. At 512 sequences, the SM120 decode kernel crashes in _get_decode_scratch. It reserves a 289 MB workspace but needs 305 MB.
Useful concurrency caps near 256 sequences. At 128 sequences with greedy decoding, aggregate throughput reached 555 tokens per second.
Re-decide at the temperature you train at
Every number so far used greedy decoding. RL does not. The policy samples at a temperature, often near 0.8, and that changes the speculative-decoding math.
So I re-ran the comparison that matters. Speculative decoding on versus off, at temperature 0.8, at both sequence caps.
Table 2. Speculative decoding at RL sampling temperature. Rows are grouped by --max-num-seqs. The benchmark used 160 client requests for the 128-sequence server and 224 client requests for the 256-sequence server.
| Sequence cap | Speculative decoding | Sustained (tok/s) | Peak (tok/s) | Mean accepted length |
|---|---|---|---|---|
| 256 | MTP-1 | 731.5 | 843.9 | 1.81 |
| 256 | off | 587.9 | 662.4 | - |
| 128 | MTP-1 | 434.9 | 590.4 | 1.79 |
| 128 | off | 339.1 | 498.8 | - |
Speculative decoding wins at both sequence caps. At 256 sequences it adds 24% sustained and 27% peak. At 128 it adds 28% sustained and 18% peak.
The winning config is MTP-1 at 256 sequences, temperature 0.8. It reached 843.9 tokens per second peak and 731.5 sustained.
This is the result I did not expect. The usual rule says speculative decoding should hurt at high concurrency. Verifying drafted tokens costs compute. At high concurrency, compute should be scarce, so verification should not pay.
That rule assumes a compute-bound GPU. On this DGX Spark setup, decode waits on weight reads. The draft’s verify tokens ride along on weights already in flight, so the extra compute is nearly free.
The same bandwidth limit that caps single-stream decode keeps speculation paying at high concurrency. On new hardware, run the comparison at the temperature and concurrency you will actually train at.
The recipe
The runnable scripts live in the companion repo, inference-recipes/inference. This post keeps the decisions and reasoning. The repo keeps the exact image tag and flags, which can drift.
You need 2 DGX Spark machines on a working RoCE link. You also need the official deepseek-ai/DeepSeek-V4-Flash checkpoint on both machines and a GB10 vLLM image with the B12X MoE path. The repo README lists the rest.
Find your network values
RoCE is the easiest thing to get silently wrong, so confirm your values first. Run preflight.sh on each machine before launch. It prints:
ibv_devices # the RDMA device name -> ROCE_HCA
rdma link show # device-to-netdev, link state -> NET_IF
show_gids # the GID table; the RoCE v2 row -> GID_INDEX
ls /dev/infiniband # the devices passed into the container
The settings that matter
GB10-scoped settings carry to other large MoEs on this hardware. Model-scoped settings change per checkpoint.
| Setting | Value | Scope | Why it matters |
|---|---|---|---|
VLLM_USE_B12X_MOE |
1 | GB10 | use the GB10 MoE kernel, not the MARLIN fallback |
RDMA --device and --cap-add=IPC_LOCK |
pass through | GB10 | let NCCL open the RoCE devices inside Docker |
NCCL_IB_HCA, NCCL_IB_GID_INDEX |
your HCA, the v2 GID | GB10 | point NCCL at the RoCE device |
--tensor-parallel-size, --nnodes |
2, 2 | GB10 | split 149 GB of weights across both machines |
--max-num-seqs |
256 | GB10 | fill the batch up to the SM120 kernel wall |
--max-num-batched-tokens |
8192 | GB10 | avoid starving speculative decoding batches |
--kv-cache-dtype, --block-size, --gpu-memory-utilization |
fp8, 256, 0.9 | GB10 | leave enough unified memory for KV cache |
IMAGE, MODEL_DIR, --served-model-name |
the model files | model | the model and its GB10 serving build |
--tokenizer-mode, --trust-remote-code |
deepseek_v4 | model | the model’s own tokenizer and code |
--speculative-config |
mtp, k=1 | model | use the draft head; k=1 wins aggregate |
VLLM_SPARSE_INDEXER_MAX_LOGITS_MB |
256 | model | V4 hybrid attention only |
Run it
git clone https://github.com/jbarnes850/inference-recipes
cd inference-recipes/inference
cp config.env.example config.env # edit for your machines
./preflight.sh # print RoCE values; repeat on the worker
./up.sh # launch both nodes, ~5 min cold start
./rl_sweep.sh # run the temp-0.8 comparison
./down.sh # stop and free the machines when done
Cold start is about 5 minutes, limited by reading the weights off disk. Serving holds about 120 GB on each machine at 0% idle use, so tear it down between runs.
What changes when the trainer is live
Everything so far measured a static server. The weights never moved. A live async RL trainer changes that because the policy updates while the server runs.
Three constraints start to matter. None of them break the recipe, but you have to design around them.
The draft head drifts
The 843.9 peak number used the model’s frozen MTP head, measured against the base policy. RL changes the main model step by step. The head was trained to predict the old policy, so its guesses match less often as training goes on.
Acceptance falls, and the speculative-decoding win shrinks with it.
Watch mean accepted length in the vLLM logs. It starts near 1.8. Below about 1.4, verifying drafted tokens costs more than it saves. At that point, drop to no speculation.
The better fix is to keep the head in sync. Update the MTP head alongside the main weights at each resync. NVIDIA’s report calls this online draft adaptation. Then acceptance can hold through training.
Each rollout has a floor
843.9 tokens per second peak at 256 sequences is about 3.3 tokens per second per rollout. The sustained number, 731.5, is about 2.9 per rollout.
That is fine for many short rollouts in parallel. It is slow for a long multi-turn trajectory that needs tens of thousands of tokens in one sequence.
Set concurrency to your fanout, not to the maximum. The 256 cap maximizes aggregate throughput. It does not maximize any single rollout.
If your rollouts are long and few, run fewer sequences so each one gets more of the machine. Tune --max-num-seqs to how many trajectories you sample at once.
Weights have to hot-swap
A static server loads once. An async trainer updates the policy every few steps. A 5-minute restart each time would erase the throughput you just won.
The weights have to swap into the running server.
vLLM supports this through an in-place weight update, with the engine briefly paused rather than restarted. That update path has to include the MTP head.
Consider this recipe a starting point - keeping weights and draft models in sync is the next challenge.
Reproduce this for a new model
The method is the sequence, not the specific model. To bring another large MoE up on GB10 as a rollout engine, walk the same checks.
- Get a checkpoint whose kernels run on GB10. Avoid datacenter NVFP4 builds, and use a checkpoint quantized for consumer Blackwell or one the GB10 serving image supports.
- Serve it across both machines with tensor parallelism of 2 if the weights do not fit in one machine’s 119 GB.
- Set the GB10 MoE kernel with
VLLM_USE_B12X_MOE=1, and confirm the engine is not using a generic fallback. - Bring up RoCE, then read the NCCL log to confirm it reports RoCE and not a TCP socket.
- Turn on speculative decoding if the model ships a draft head, and sweep k. Expect k=1 to win aggregate.
- Raise
--max-num-seqsuntil throughput stops climbing or the SM120 kernel caps you near 256, and set--max-num-batched-tokens 8192. - Re-run the speculative-decoding comparison at your real sampling temperature and concurrency, and measure rather than assume.
The numbers differ by model, but the order and the checks carry over.
What this shows
The climb from 31 to 843.9 was almost entirely systems work.
Speculative decoding helped at high concurrency because this DGX Spark setup was limited by weight reads, the opposite of what the compute-bound rule predicts.
The next recipe builds the other half, the async RL engine that runs this server and keeps the draft head in sync.