Running async RL on my DGX Spark cluster
Codebase
Bridge code, configs, smoke scripts, and run lineage for this recipe.

Figure 1. Polar’s rollout architecture (from the Polar README, Apache 2.0). The Trainer is NeMo RL’s async RL loop on one Spark. The Inference Server is vLLM on the other. The Rollout Server and Gateway Nodes are Polar, colocated with the inference engine. The weight-sync line is the NCCL broadcast this post measures, and the trajectories edge (messages, token_id, logprob, mask, reward) is what the collector reshapes into NeMo RL replay-buffer groups.
Once training and rollout serving are separate, async RL becomes a data-movement problem. The largest object moving through that system is the policy weight sync after each learner step.Weight sync copies the trainer’s updated policy weights into the rollout sampler so new samples come from the current policy. On a non-colocated setup it is a network broadcast, not a local copy.
The last recipe pushed a rollout engine to its throughput ceiling. Luke Huang’s frontier async-RL survey is the best map I have seen of that problem. vLLM’s native RL APIs and TRL’s delta weight sync fill in the serving and weight-sync pieces.
I stood that loop up on my own hardware, a DGX Spark cluster of 2 machines, one training Qwen3-4B and the other serving rollouts. NeMo RL owns the learner. Polar runs the agent harness and builds the trajectories. The collector between them is deliberately thin, and one invariant holds the boundary. Polar collects native trajectories, and NeMo RL decides which ones are still valid to train on.
- Why async RL is a systems problem
- The rollout server collects, the trainer decides
- Defining your config
- The recipe
- Profiling the wallclock
- Recap
Why async RL is a systems problem
Async RL is a contract between four moving parts. Hugging Face’s survey of 16 open-source RL libraries is a catalog of the ways frameworks keep those four aligned.
-
The rollout server generates trajectories from a specific policy version. It needs high throughput, but it also has to preserve the exact training data the learner will consume, down to the token ids and logprobs.
-
The learner updates the policy and decides which samples are still valid. This is where rollout age, replay, off-policy correction, rewards, and optimizer state stop being knobs and become training semantics.
-
The weight-sync path moves fresh weights from the learner into the inference engine. If this path is slow, the rollout server keeps sampling from stale policy versions and the learner trains on older data. On one machine this is nearly free. Split across two, it becomes the single largest cost in the step.
-
The trajectory contract preserves tokens, logprobs, rewards, masks, and policy-version metadata across the boundary. It matters because a small silent mismatch can turn valid rollouts into corrupted training data, and nothing upstream will tell you it happened.
The rollout server collects, the trainer decides
Polar is a trainer-agnostic rollout layer. It separates agent harnesses (OpenHands, mini-swe-agent, Terminus2) and environment backends (Docker, Modal, EC2) from trainer logic, so each can change independently. Evaluation, distillation, and RL all sit behind one rollout endpoint where a client submits a task and receives a trajectory. NeMo RL fills that client role here, but nothing on the rollout side is tied to NeMo.
The collector’s own docstring draws the boundary.
This module intentionally keeps the integration surface small: NeMo still owns
the trainer, replay buffer, staleness window, importance-sampling correction,
and vLLM weight sync. The collector only replaces NeMo's default rollout actor
with one that submits Polar tasks and converts the resulting traces into the
same per-prompt replay-buffer group shape NeMo already samples.
Polar runs the harness and builds the trajectory. The collector is a single actor swap, so the rest of the trainer’s async machinery runs unmodified.
Before a group of rollouts reaches the replay buffer, it checks that every session produced a usable trace and raises if one did not.
if valid_sessions < group_sessions:
raise RuntimeError(
"Polar collector refusing invalid group before replay-buffer add: "
f"valid_sessions={valid_sessions} group_sessions={group_sessions}"
)
The collector fails the step rather than hand the trainer a silent short group that would corrupt the gradient. A second check warns when reward variance across the group falls below 1e-5, the zero-advantage case GRPO cannot learn from.
The trajectory it does pass has to survive tokenization without drift, because the trainer has to see the exact token ids the sampler saw. Token ids come from the inference backend, not from re-tokenizing text. The gateway asks vLLM for token ids and per-token logprobs directly, and the assistant tokens in the merged trace are the raw ids the model sampled.
Byte-pair encoding is not round-trip stable. [fish, ing] can re-tokenize to [fishing] in the next turn’s prompt, shifting every token after it. Prime Intellect’s renderers library documents the same class of bug from the other side and puts a number on it. Letting the inference engine re-render full history each turn broke token identity on 32 of 64 rollouts with Qwen3.5-35B-A3B, where a bridge that never re-renders broke none.
Polar sidesteps it by routing each completion on canonical prompt tokens only, never on the sampled response ids.
def _find_extendable_chain(prompt_ids, chain_tips):
"""A completion continues a chain iff its prompt begins with that
chain's last prompt. The compared prefix is two server-side
tokenizations of the same text, so BPE re-tokenization of the
sampled response never enters the decision.
"""
best_idx, best_len = None, -1
for idx, tip in enumerate(chain_tips):
n = len(tip)
if n > best_len and 0 < n <= len(prompt_ids) and prompt_ids[:n] == tip:
best_idx, best_len = idx, n
return best_idx
The merged stream takes assistant bodies from the raw sampled ids, which keep their real logprobs and a loss mask of 1. It takes interstitials (tool results, chat-template glue) from the canonical next-turn tokens, which get a zero loss mask. Nothing the model generated is decoded and re-encoded.
The serving side has to pause, drain, refit, and resume. When the trainer is ready to push new weights, the collector pauses generation through Polar’s own proxy. That proxy is an asyncio.Condition gate that stops accepting new requests and drains the in-flight ones before the weight update. Then it resumes. vLLM shipped a native RL pause-and-weight-transfer API in May. I keep the gate on Polar’s side here because the trainer talks to one stable Polar endpoint whether the engine underneath is vLLM or SGLang.
Defining your config
You define the training algorithm in the config. The policy-gradient family shares one ClippedPGLossFn, and GRPO, Dr. GRPO, RLOO, CISPO, GSPO, and DAPO are each a set of overrides on that one loss. GRPO adds no overrides, so it is the base config. CISPO is the same loss with a different clip. It sets use_cispo=true, token-level loss, per-token importance ratios, and a clip range of (1, 4).
I checked that this holds on GPU, not just at config-compile time. GRPO and CISPO at matched shape on the same prompts produced identical reward distributions and landed in the same weight-sync band, 251 and 237 seconds, a gap inside run-to-run noise. Switching the objective changed the config and nothing else in the launch path.
The recipe
The runnable experiment specs and smoke scripts live in the repo, jbarnes850/ProRL-Agent-Server.
| Setting | Value | Why it matters |
|---|---|---|
NRL_REFIT_SKIP_OPT_OFFLOAD |
1 | skips the optimizer CPU offload when inference is on another machine, the 131x weight-sync fix |
NCCL_TRANSPORT |
roce | routes the weight-sync broadcast over RDMA. Confirm Using network IB in the log |
NRL_REFIT_BUFFER_MEMORY_RATIO |
0.01 | sizes the weight-broadcast staging buffer with headroom on unified memory |
gpu_memory_utilization |
0.5 | safe band is 0.35 to 0.5. Both 0.65 and 0.9 OOM the shared pool |
max_num_seqs |
256 | rollout concurrency for the group |
max_num_batched_tokens |
16384 | batch headroom for the vLLM engine |
precision.train |
bfloat16 | the weight-sync payload is always this dtype |
precision.rollout |
fp8 | measured both ways, fp8 is fine here |
kv_cache_dtype |
auto | FP8 KV cache is a separate backend spike, out of scope |
async_grpo.lag |
1 | max trajectory age. NeMo turns on importance-sampling correction for async mode |
| rollout shape | 8 prompts x 4 generations | one group per prompt |
IMAGE / NEMO_RL_REF |
c236061b |
the pinned NeMo RL image with the CISPO config key |
The launch path is two commands, one to validate the spec against the trainer’s real config loader with no GPU, one to run it across the cluster.
# no-GPU gate: apply the compiled overrides through NeMo RL's own config loader
python scripts/experiment/validate_against_nemo_loader.py \
examples/experiments/qwen3-4b-instruct-basic_arith-grpo-fp8-rollout-8x4.yaml
# launch the two-machine run
python -m nemo_polar_bridge.experiment.cli launch \
examples/experiments/qwen3-4b-instruct-basic_arith-grpo-fp8-rollout-8x4.yaml \
--store runs/lineage --out runs/<slug>
Profiling the wallclock
Weight sync was about 85% of the step. At the fp8, RoCE baseline it took 226.5 seconds across 3 seeds, against a step of about 270, while generation and policy-training compute stayed healthy. The cost scaled with the model, not the rollout, so I went after the transfer.
A weight-sync design has 2 moving parts, transport for how the bytes move and payload for what you send. This weight-sync guide is the cleanest treatment of that split. This loop broadcasts the full bf16 weights over NCCL, so I tested both.
Failure modes
RoCE was the biggest win in the last recipe, so I moved the broadcast off the TCP socket it had been running on. It cut weight sync 5 to 7% and no more. GPUDirect RDMA would have been next, but nvidia_peermem refuses to load on GB10 at all, so the platform rules that out.
Then I tested the payload. FP8 rollout precision should have cut the transfer, but it did not, because the broadcast casts to the training dtype, bf16, and vLLM requants to fp8 after receipt. I made the broadcast itself fp8, bit-identical to the engine’s own blockwise cast across all 41 tensors. That dropped the payload 45%, from 8.04 to 4.41 GB. Weight sync did not move, 231 seconds against 226, inside the noise.
RoCE bought only single digits, GPUDirect was unavailable on GB10, and a 45% smaller payload did not move the step. An 8 GB broadcast over a 200 Gb/s link is about 0.3 seconds, under 1% of weight sync, so I stopped tuning the transfer and profiled the refit.
The profile put 98% of weight sync in a single phase. The transfer itself was 1.7 seconds. The other 227 were offload_before_refit, moving the roughly 32 GB Adam optimizer state from GPU to CPU, one tensor at a time, before every sync.
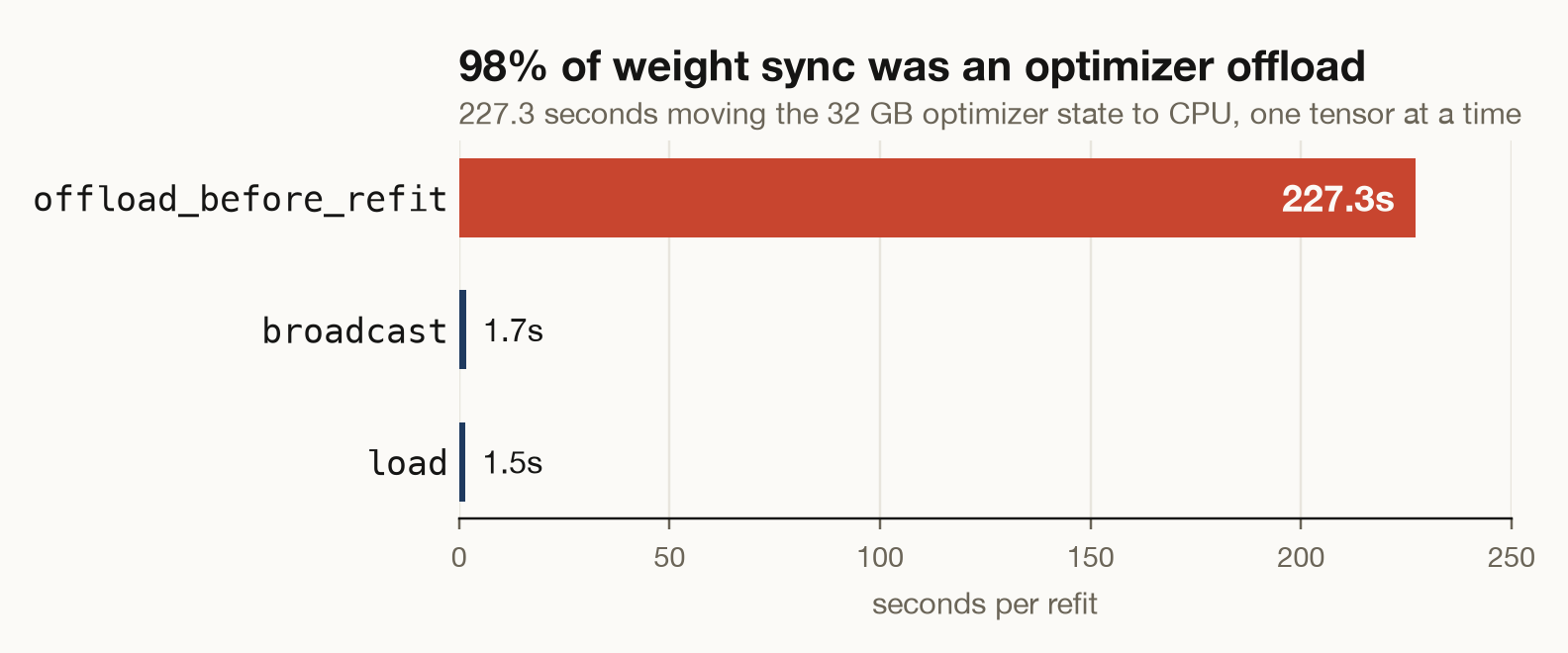
Figure 2. A per-phase profile of one refit. The optimizer offload is 227.3 of the 231 seconds of weight sync, and the actual transfer is under 2 seconds. The phase names are the profiler’s own.
That offload is a colocated-serving guardrail. NeMo RL uses it to clear trainer-card memory before refit, but this run serves rollouts on the other Spark. On GB10’s unified pool, the guardrail becomes a 227-second copy inside the same physical memory. NeMo RL’s own code comment warns against running it in non-colocated mode.
The fix is to skip it when the engine is remote. The optimizer stays on the training GPU, the matching onload becomes a no-op, and training is bit-identical, because the optimizer is never read during the broadcast. Weight sync dropped from 226.5 seconds to 1.73, a 131-fold cut. The 3 seeds landed at 1.73, 1.73, and 1.74, near-deterministic. The step went from about 270 seconds to 42, and weight sync fell from about 85% of the step to 4%. Policy training dominates now.
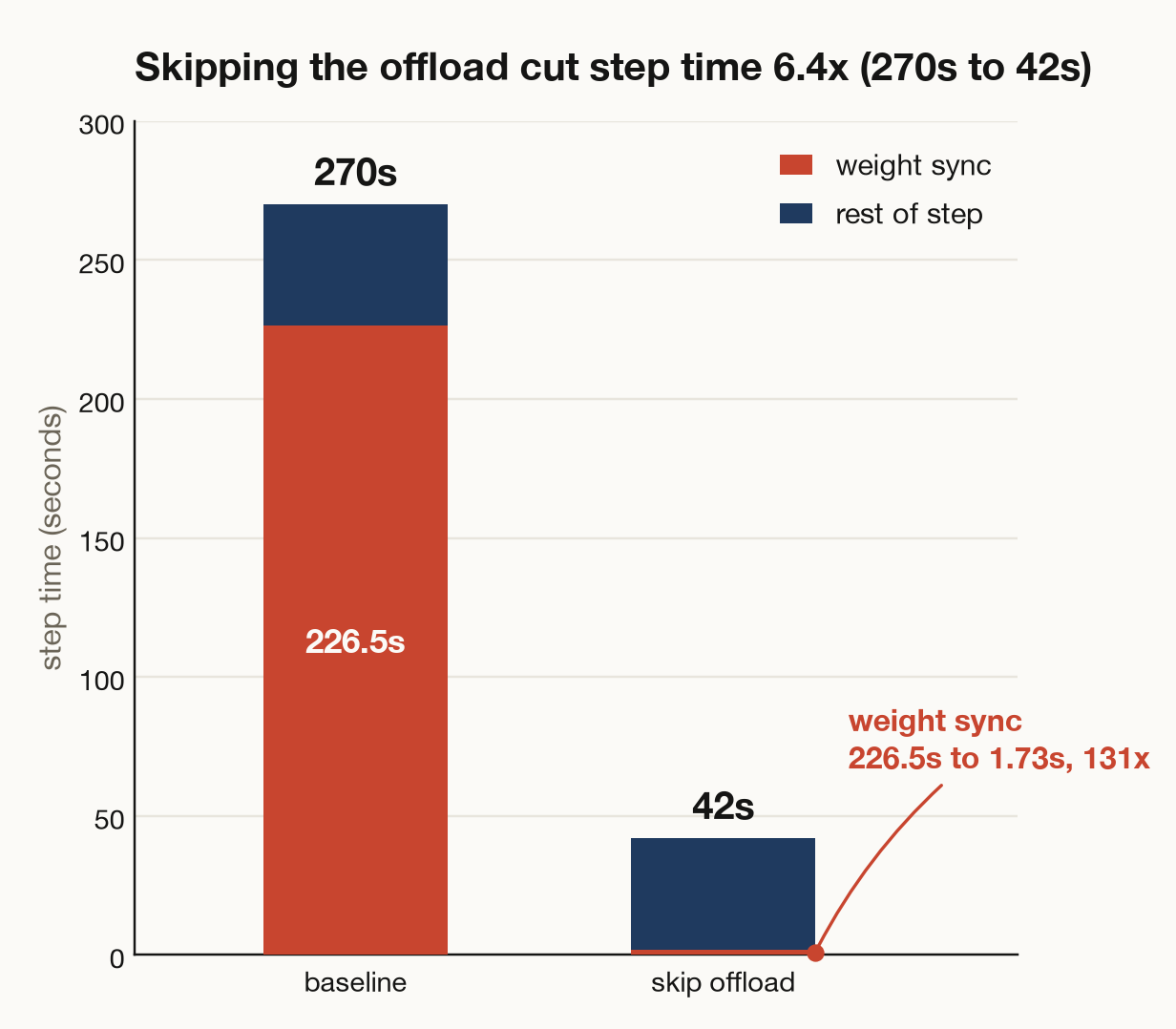
Figure 3. Step time before and after skipping the offload on a non-colocated trainer. The step drops 6.4x, from 270 to 42 seconds, as weight sync collapses from 226.5 to 1.73 seconds. What remains is dominated by policy training.
Recap
The transfer was 1.7 seconds; the other 227 were an optimizer offload to CPU that frees memory for a colocated engine this topology does not run. Skipping it when the engine is remote cut weight sync 131-fold, from 226 seconds to 1.7, from about 85% of the step to 4%. The transport and payload checks bounded the failure to the trainer side, which pointed at the offload.
Agentic RL is sample-hungry, so inference throughput matters, but raw tokens per second only help if the rollout server, weight-sync path, replay buffer, and learner agree on what each trajectory means.