Mechanistic Interpretability for Multilingual LLMs
Working technical report. Code and artifacts at github.com/jbarnes850/multilingual-interpretability.
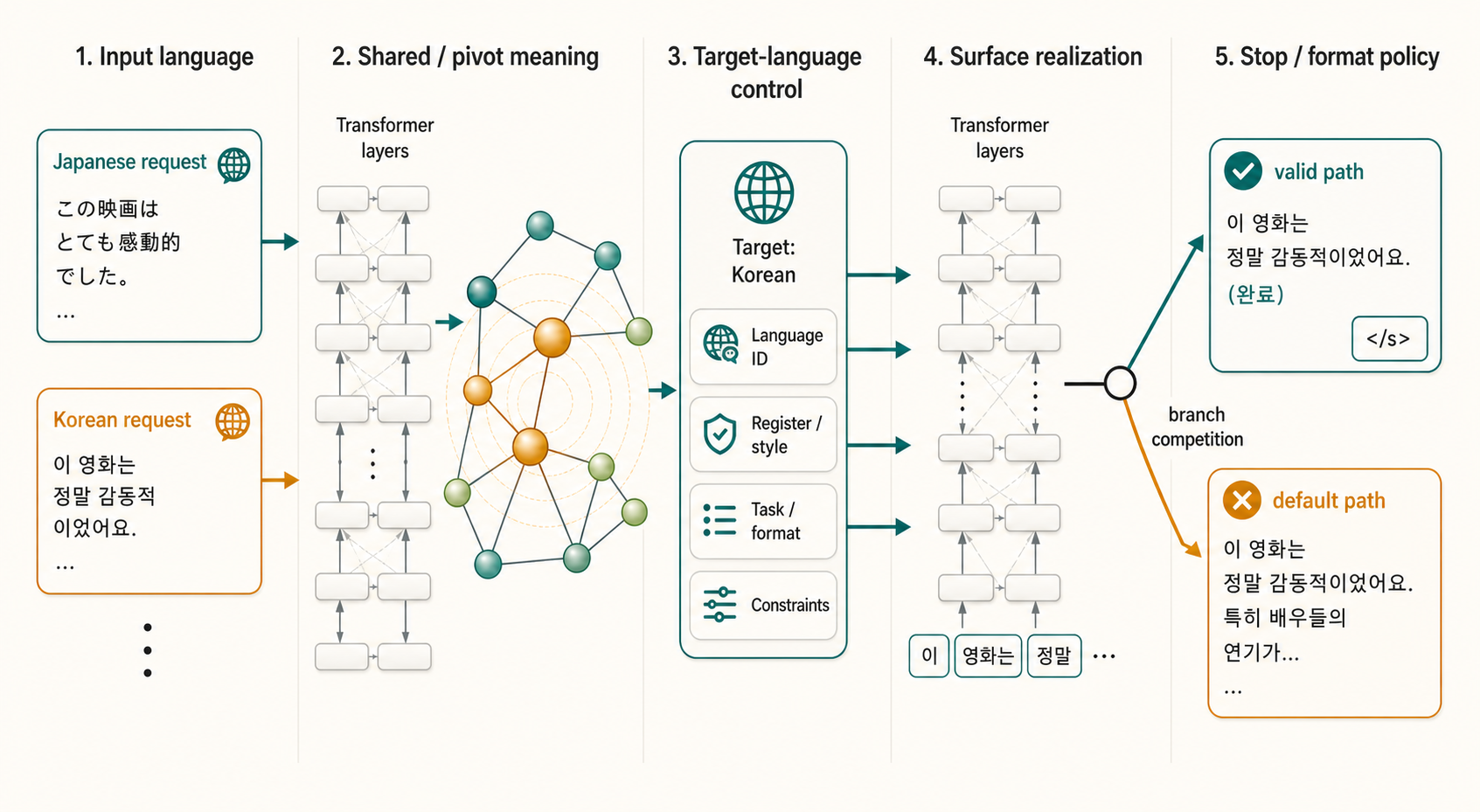
Conceptual diagram of how activations flow through the model. Geometry is illustrative; the measured numbers are in the tables below.
Language is an instruction
Arrival is one of my favorite movies. The film turns the Sapir-Whorf hypothesis, or linguistic relativity, into a compelling story where Louise Banks learns the nonlinear written language of the Heptapods, and the language changes how she perceives time.
Language is not a neutral wrapper around thought. It shapes attention, social meaning, hierarchy, politeness, ambiguity, and what counts as a complete answer. It changes what a speaker expects another person to infer without saying. It changes what sounds natural, respectful, evasive, blunt, technical, legal, or wrong.
While I’m not sure that I’ll be talking to Heptapods anytime soon, LLMs show something adjacent, the language of a prompt can change the behavior the model realizes. Basic translation is better than it has ever been, with systems like TranslateGemma sharpening quality through supervised fine-tuning, reward models, and human evaluation. But translation quality is only the first step in understanding language.
This post explores how a model turns a language requirement into the right behavior while preserving meaning, respecting culture and domain, maintaining entities, following format, and stopping at the right boundary. Each is a constraint, and they often pull against each other.
The recent literature keeps pointing at the same structural gap.
- Cultural nuance benchmarks find that grammatical adequacy is not the same as cultural resonance. Idioms, puns, holidays, and embedded cultural concepts remain hard even when the output looks fluent.
- Language and culture are entangled: changing the language of a prompt can change the cultural context the model uses, and low-resource languages often receive lower-quality open-ended answers.
- Multilingual instruction-following is not just English instruction-following translated. M-IFEval shows wide variation across languages and instruction types, while Marco-Bench-MIF finds high/low-resource gaps, script-specific challenges, and failures from machine-translated evaluation data.
- Translation can still hallucinate. HalloMTBench separates failures where the model detaches from the instruction from failures where it detaches from the source, and multilingual hallucination work shows that hallucination measurement itself is still often English-centric (Islam et al.).
I use Japanese and Korean as the core languages and test Cohere’s Tiny Aya family. Both languages use scripts, word structures, and segmentation conventions that differ from English, which makes them a stronger probe of where things go wrong than a straight English-to-English benchmark.
Our core research question is:
How does a multilingual model separate meaning from language, and where do base and post-trained model checkpoint differences appear along the route from latent representation to decoded behavior?
Core Evaluation
We decompose the task into five mechanisms.
| Mechanism | Question | Evidence used here |
|---|---|---|
| Meaning preservation | Did the model retain the semantic content? | Are same-meaning Japanese/Korean prompts close internally? Do outputs resemble references? |
| Target-language identification | Did it know the requested output language and script? | Can a simple readout tell which target language is requested? Does the model put probability mass on the right script? |
| Surface realization | Did the right next token win the final branch? | Logit-lens rank of valid vs greedy tokens through layers; final branch margin |
| Format/entity fidelity | Did it preserve business constraints? | Numbers, dates, URLs, entities, quoted spans, JSON/schema validity |
| Stop/continuation control | Did it stop at the valid answer boundary? | End-token scores, prefix-valid failures, overgeneration traces |
Was valid behavior available somewhere inside the model, and if so, where did it lose?
Why Tiny Aya
Tiny Aya gives a clean experimental handle because the family contains a base model and posttrained variants:
| Model | Role in this study |
|---|---|
tiny-aya-base |
the pretrained multilingual model, before any instruction tuning |
tiny-aya-global |
the globally balanced instruction-tuned variant |
tiny-aya-water |
a region-specialized merge whose cluster includes Japanese and Korean |
The Tiny Aya report frames these as compact multilingual models (3.35B parameters, 36 layers) trained on 70 languages and refined through region-aware posttraining.
We use a small, text-only multilingual subset of enterprise tasks drawn from public datasets.
| Source | Rows | Role |
|---|---|---|
| FLORES+ | 24 | Japanese/Korean translation calibration |
| Marco-MIF | 30 | target-language and instruction/format control |
| DataPilot Japanese Function Calling | 10 | Japanese tool/schema fidelity |
| Korean law dataset | 10 | Korean legal document schema transform |
| Korean legal QA | 10 | grounded Korean legal adequacy |
Core experiments
I ran three experiments on the same 84-row test set.
- Sampling: generate 16 outputs per row and ask whether valid behavior exists in the model’s distribution.
- Verification: score each candidate with a layered verifier built from meaning preservation, target-language control, format/entity retention, and stopping.
- Internal tracing: compare the valid sampled path against the default path to see where the valid continuation appears, loses, or disappears inside the model.
For sampling, I ask whether the model’s default decoding or likelihood ranking actually selects the valid behavior.I use “greedy” to mean the default highest-probability decoding path. In theory, greedy decoding always chooses the top next token. In practice, modern LLM inference can still be nondeterministic because batching, kernel choices, and floating-point reduction order can slightly change logits. See Thinking Machines Lab, Defeating Nondeterminism in LLM Inference.
Each candidate was scored with a layered verifier built from the five mechanisms above. A valid candidate had to preserve meaning where a reference existed, use the requested target language and script, preserve protected spans, satisfy format constraints, and stop at the right boundary.The verifier is deterministic. It checks observable constraints such as script, JSON validity, quoted spans, numbers, dates, URLs, entities, legal references, and reference similarity where a public reference exists.
I measured four quantities:
- Greedy valid: whether the default output passed the verifier.
- Any valid at N=16: whether any sampled candidate passed.
- Max likelihood at N=16: whether the model’s own likelihood ranking selected a valid candidate.
- Verifier + likelihood at N=16: whether deterministic checks could select a valid candidate, using likelihood only as a tie-breaker.
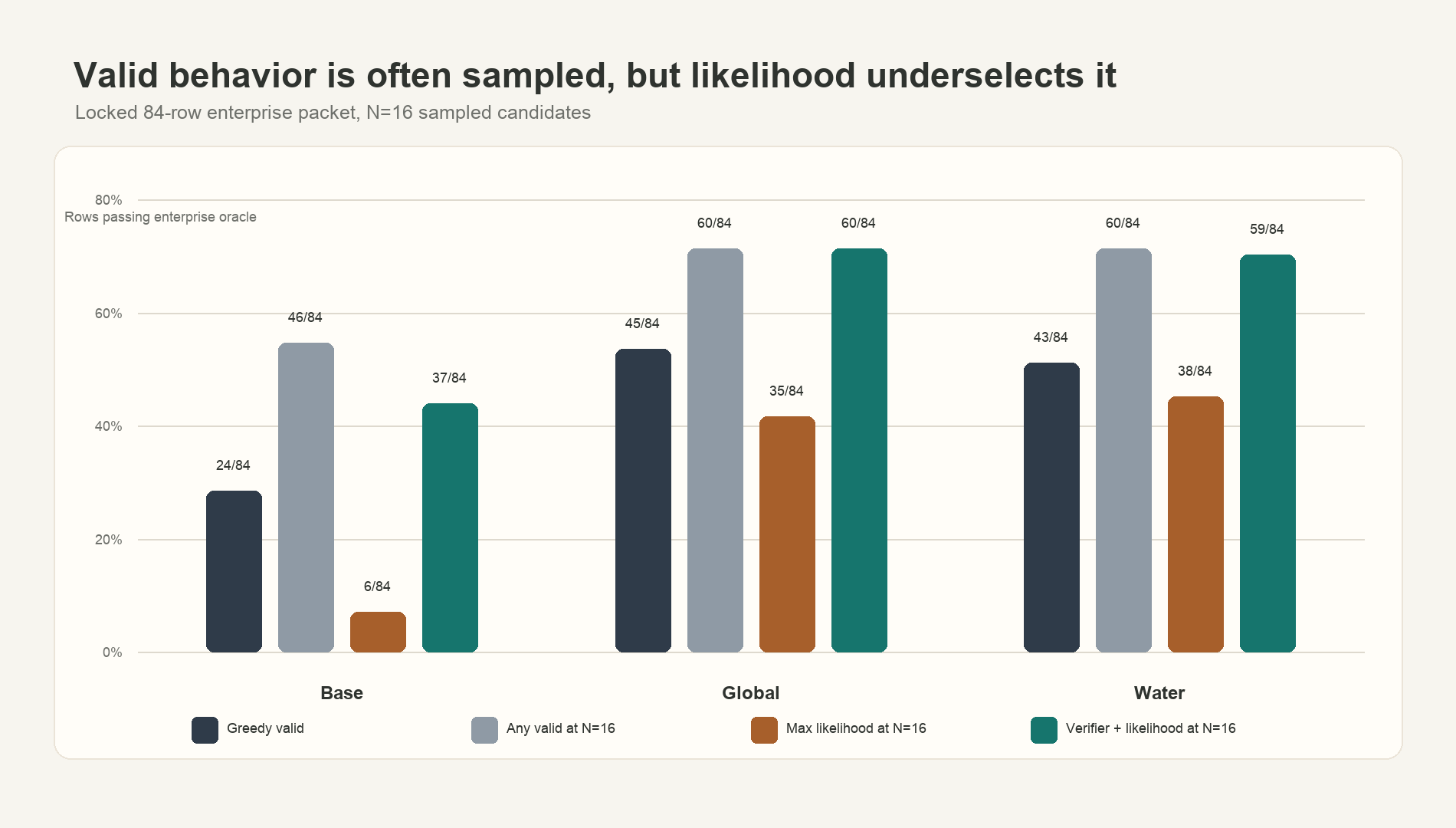
On the 84-row test set, valid candidates often exist at N=16. Max-likelihood selection is a poor selector: it underperforms greedy for all three models. A hard verifier recovers most of the available valid candidates for Global and Water.
| Model | Greedy valid | Any valid at N=16 | Max likelihood at N=16 | Verifier + likelihood at N=16 |
|---|---|---|---|---|
| Base | 24/84 | 46/84 | 6/84 | 37/84 |
| Global | 45/84 | 60/84 | 35/84 | 60/84 |
| Water | 43/84 | 60/84 | 38/84 | 59/84 |
Valid behavior exists in the model’s distribution, but default decoding and sequence likelihood do not reliably pick it. The highest-likelihood candidate is often not the best candidate because enterprise-valid answers must satisfy several constraints at once.
Why does the valid path lose?
Looking inside the model
To understand how these models work, I measured seven internal or behavioral signals across Tiny Aya Base, Global, and Water.An internal signal is a measurement taken from model activations, logits, or hidden states rather than only from the final output string.
- Meaning alignment: do same-meaning Japanese and Korean prompts land closer internally than shuffled controls?
- Target-language ID: can a simple readout from the hidden state tell which output language the prompt requests?A readout is a lightweight classifier trained on activations. If it can recover target language from a layer, that layer contains linearly accessible information about the requested language.
- Script control: does the model put probability mass on tokens from the requested script?
- Format/entity retention: do outputs preserve exact constraints such as numbers, dates, URLs, entities, quotes, and JSON shape?
- Valid-token availability: does the valid next token become rank-available before final decoding?
- Branch competition: does the valid continuation beat the default continuation at the final branch?
- Stop readiness: does the model assign stronger end-of-answer probability to valid endings than greedy-invalid endings?EOS, short for end-of-sequence, is the special token a model emits to signal that the answer is finished. A confident EOS at the right position is what stops generation cleanly.
Three lenses on the same 36-layer network. Each pressure becomes active at a different layer, then they compete near decoding.
Signals are placed by their measured peak layer; the band shows the layer range where each signal is active.
One representative Base case. Valid token becomes available mid-network, then loses the final-layer contest by ~1.8 nats. Per-model distributions are in the tracing tables.
- greedy valid
- 24/84
- mean valid rank
- 228.86
- final branch margin
- −0.78 nats
Valid behavior exists, but the model rarely picks it.
- greedy valid
- 45/84
- mean valid rank
- 1.74
- final branch margin
- −0.83 nats
Selection sharpens; valid continuations land near the top of the distribution.
- greedy valid
- 43/84
- mean valid rank
- 1.81
- final branch margin
- −1.55 nats
Same gains as Global, with a slightly tighter local route.
Three measurements per model. Bars are scaled within each row to make the relative move visible at a glance.
Meaning alignment is already visible early. Target-language identity is nearly perfectly recoverable from middle layers. But surface realization is where it breaks: the valid continuation can be highly ranked and still lose the final branch contest.
So the model is not running a clean assembly line where it first builds language-free meaning and only later adds Japanese or Korean. The late layers decide which pressure wins.
This matches the surrounding literature in broad shape. Wendler et al. argue that Llama-family models route through an English-like intermediate representation, and Schut et al. find that multilingual LLMs can make key decisions in a representation space closest to English. Paths Not Taken decomposes multilingual factual recall into recall and target-language realization. Translation-mechanism work such as Exploring the Translation Mechanism of LLMs makes the same broad point: translation is not one operation. It is a route through source features, latent representations, and target-language realization.
Tracing
Once valid sampled outputs existed, I traced the branch point.
A branch point is the first token where the valid sampled output and the default output diverge. In one path, the model moves toward the valid answer. In the other, it moves toward the default answer that fails the verifier.This is a trajectory comparison. I compare the hidden-state and logit behavior along a valid sampled continuation against the behavior along the default continuation.
At each branch point, I asked three questions:
- Does the valid token ever beat the default token in any layer?
- Under teacher forcing,Teacher forcing means scoring a known continuation by feeding the model the correct previous tokens at each step. It lets us ask whether the model can support a trajectory even if it would not choose that trajectory on its own. does the model score the valid continuation coherently token by token?
- By the final layer, which token wins?
Results:
| Model | Cases | Valid leads in some layer | Median best layer | Wins at final | Mean valid−default Δlogprob |
|---|---|---|---|---|---|
| Base | 21 | 20 | 17 | 5/21 | -1.77 |
| Water | 17 | 16 | 18 | 1/17 | -1.70 |
| Global | 15 | 14 | 16 | 2/15 | -1.05 |
The valid path often leads in the middle of the network, then loses by final decoding. In Global and Water, the valid token sits near the top of the distribution at decoding (median rank 2-3 against the default’s median rank 1). But the final branch margin still favors the default invalid continuation.
That is different from not knowing Japanese or Korean. The model has a valid route, but the decode-time competition selects a nearby invalid route.
Some failures are even simpler. In one Base case, the valid answer was a prefix of the default answer. The model had already said enough, then continued into invalid output.
This matters because the failure is localizable. The model can carry a valid trajectory internally, then lose at the final selection step or fail to stop after a valid answer.
What changes with post-training
The Tiny Aya report makes the comparison useful because Base and the post-trained models sit on different sides of the training process. Base is the pretrained multilingual model, trained for 6T tokens across 70 languages, code, and a multilingual cooldown mix. Global is what happens when that substrate is shaped with instruction data, translation expansion, cultural adaptation, synthetic teacher completions, and a light preference-tuning step that anchors identity and safety. Water is built on top of Global by training a regional checkpoint (a cluster that includes Japanese and Korean) and merging it back into Global via SimMerge, a checkpoint-merging procedure.
At N=16, Base already produces valid candidates on 46 of 84 rows. The capability is there.
Global and Water make that valid route easier to realize.
- Greedy valid rows rise from Base
24/84to Global45/84and Water43/84. - Exact invariant retention rises from Base
0.753to Global0.904and Water0.911. - Mean valid final rank improves from Base
228.86to Global1.74and Water1.81. - Valid endings have higher EOS logprob than greedy-invalid endings across all three models: Base
+1.55, Global+1.82, Water+1.03.
Post-training made the existing behavior more selectable, better formatted, and easier to stop.
A trace shows that a valid path appears inside the network. It cannot show that the internal state causes the model to choose that path. The next step is causal: if a late hidden state carries the target-language decision, moving that state between models should move the behavior with it.
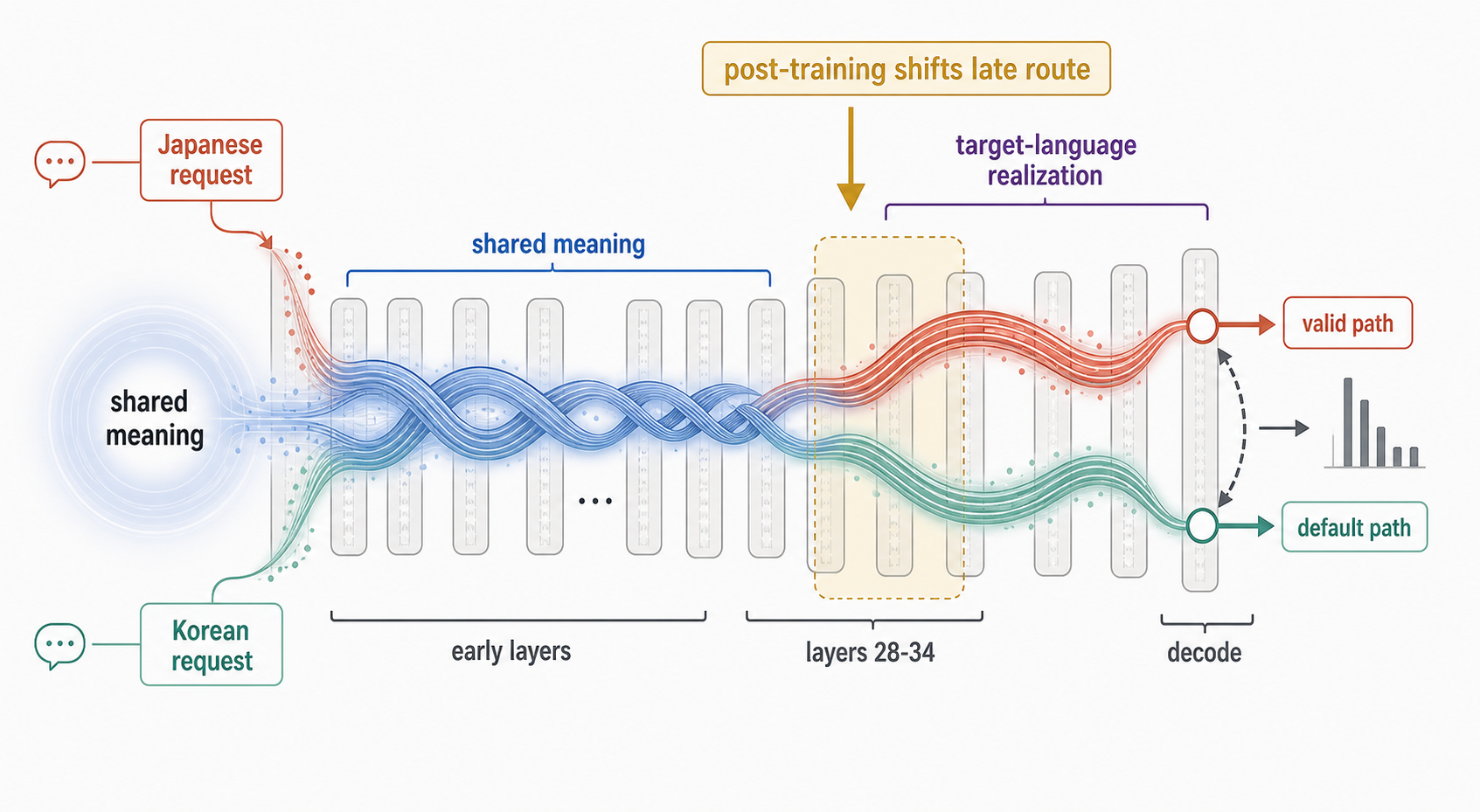
Conceptual mechanism from the causal experiments. Early layers preserve shared meaning across Japanese/Korean prompt pairs. Late layers separate into target-language realization paths, where post-training changes the branch competition near decoding. Geometry is illustrative; the evidence is in the tables below.
Digging Deeper in the Internals
I tested four more translation directions: Japanese-English, Korean-English, Arabic-English, and Japanese-Chinese. Across all three Tiny Aya models, all 12 model-pair conditions showed a same-meaning signal peaking around layers 27-30.The same-meaning signal is the cosine gap between paired prompts with the same meaning and rotated prompts with different meanings. It asks whether meaning is preserved beyond surface language overlap.
Post-training did not do the same thing everywhere.
| Case | What happened | Read |
|---|---|---|
| Translation | Base already had the route; Global and Water sharpened it | post-training amplified an existing route |
| Paired instruction-following | Base had no clean late peak; Global and Water peaked at layer 26 |
post-training installed a late route where Base had none |
| Single-language enterprise tasks | function calling, Korean law, and Korean legal QA reorganized around layers 13-21 |
post-training reorganized middle layers, not the late translation route |
Tiny Aya does not have one universal multilingual circuit. It has routes. Some are already present in Base. Some are made more selectable by post-training. Some are task-specific and start earlier than the translation route.
Residual patching at layer 34 reproduced the translation effect: Global into Base moved the output by +2.79, and Base into Global moved it by -5.55.Residual patching replaces the model’s hidden state at a chosen layer and token with the hidden state from another run. If behavior changes, that hidden state was causally involved. Korean law also moved in the expected direction, with the layer 34 crash reproducing at -3.38 nats.A nat is a unit of log probability. A negative shift means the patched model made the target continuation less likely.
But Marco-MIF was different. Layer 26 patching moved the first generated token by +2.25, then disappeared. It fixed 0/8 full outcome cases.
The patch shifted the next-token decision but couldn’t carry the route through the rest of the answer. A single residual patch is a flashlight: it shows where the route runs, not how to rebuild the road.
The SVD decomposition of the Global-minus-Base weight change at layer 34 was broad: 1564 of 2048 directions were needed to capture 90% of the change.SVD, short for singular value decomposition, sorts a weight change into a ranked list of directions, strongest first. If the first few directions explain most of the change, the change is “low-rank.” Here, more than a thousand directions were needed. A small SVD edit still moved Base toward Global by +0.22 chrF,chrF is a translation-similarity score. It compares characters in the output to a reference, and higher means closer. The +0.22 here is a lift toward Global’s continuation, not toward the human reference text. but no single direction carried the route.
The sparse-autoencoder result pointed the same way.A sparse autoencoder learns a dictionary of activation features. If post-training created a small named feature, this is one place we might expect it to appear. The SAE learned usable reconstructions, but it did not find a single feature that explained the post-training change. The top feature discrimination score was numerical noise (9.5e-07). The Base and Global SAE feature dictionaries were almost identical, lining up at a cosine similarity of 0.999.
So the change is not best described as “post-training added the Korean feature.”
The better description is: post-training changed routing. It changed which existing directions fire, when they fire, and which path wins near decoding.
This sits in the same family as recent work pushing toward parameter-level explanations of multilingual behavior, including Goodfire’s adVersarial Parameter Decomposition (VPD). Our result is at a smaller scale, focused on tracing the route, testing whether it was causal, then asking whether it factors into a small set of named features.
Tiny Aya often has the right behavior somewhere before decoding. Post-training makes that behavior easier to realize. But the mechanism is spread across many parts of the network, varies by task, and only controls the very next token. Carrying the route across the whole answer needs more than a single internal nudge.