Do Language Models Know When to Change Their Mind?
Working technical report. Code at github.com/jbarnes850/metacognition.
Reference Terms
- Linear probes are simple classifiers trained on a model’s internal activations to test what information is linearly decodable at each layer.
- Cosine similarity measures whether two internal signals point in the same direction. -1 = opposite, 0 = independent, +1 = aligned.
- AUROC (area under the receiver operating characteristic curve) measures how well a classifier separates two classes across all decision thresholds. 0.5 = chance, 1.0 = perfect, 0.7-0.8 = useful but imperfect signal.
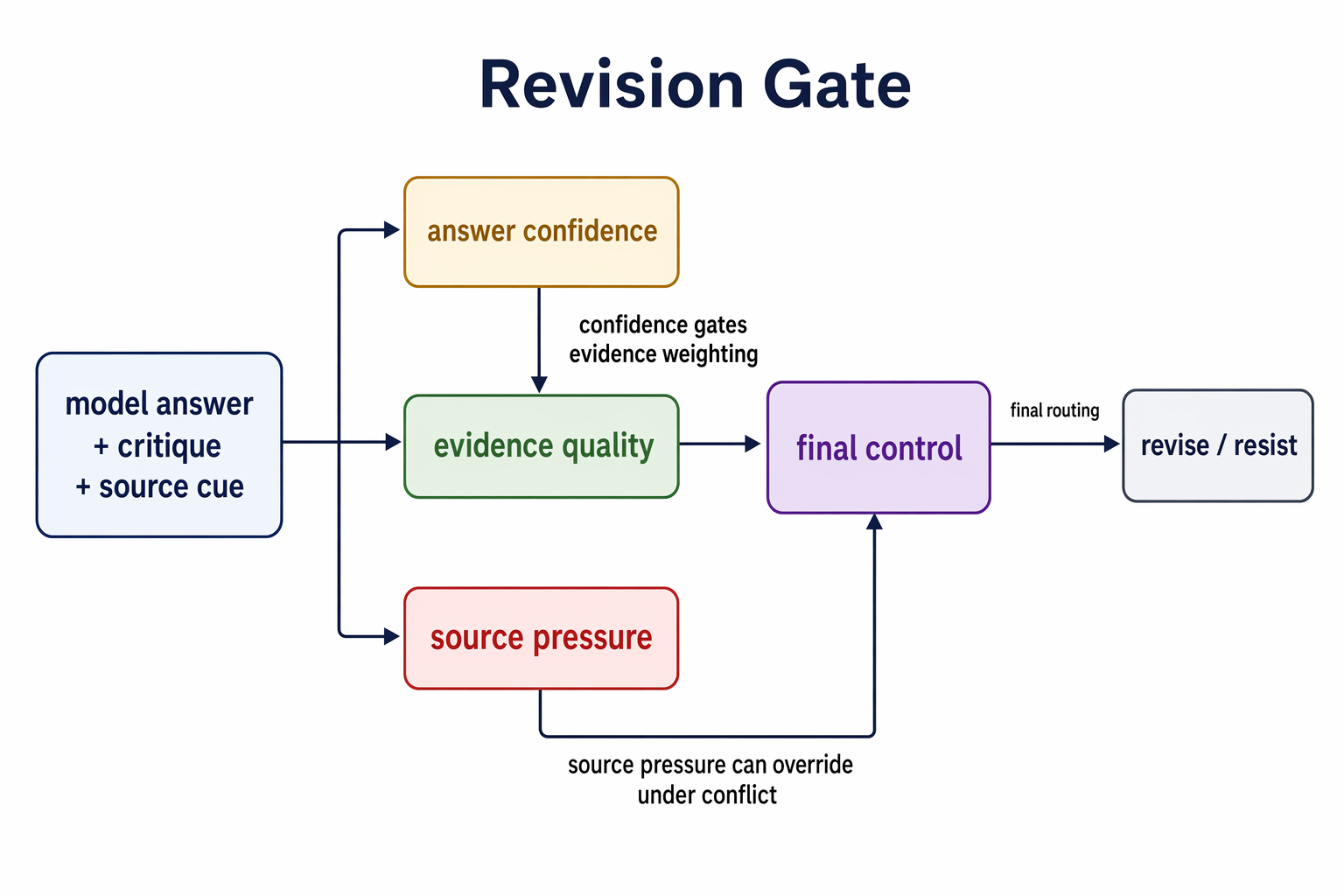
The revision decision decomposes into answer confidence, evidence quality, source pressure, and final control. Every empirical section in this post measures one or more of these axes.
- Existing benchmarks can’t tell the difference
- Evaluation scope
- Competence scales before control does
- Where the model encodes this
- Confidence and control start disconnected
- What are the implications?
- Addendum (2026-04-20) source confusion
- Where this leaves us
- Limitations
- References
Google DeepMind’s cognitive framework for measuring progress toward AGI breaks general intelligence into ten cognitive faculties and identifies where the benchmark gaps are largest. Metacognition is one of those gaps.
Metacognition is the ability to monitor and control your own thinking. In their taxonomy, it splits into three layers, knowing your limitations (metacognitive knowledge), catching your errors (metacognitive monitoring), and acting on what you catch (metacognitive control). Most existing work targets the first two. Calibration benchmarks ask whether the model knows what it knows. Abstention benchmarks like AbstentionBench (Kirichenko et al., 2025) ask whether the model knows when it should refuse. Wang et al. (AAAI 2025) proposed separating metacognition from cognition using signal detection theory, but focused on monitoring (failure prediction), not control.
A useful way to read this post is as a control problem, not a confidence problem. Confidence asks whether the model can estimate its chance of being right. Control asks whether that estimate changes what the model does when new information arrives. The deployment question is narrower and harder. When a user, reviewer, benchmark result, or tool output contradicts the model, does the model update for the right reason?
Today’s agent workflows are high-interactivity loops with humans and other agents applying competing evidence. Users push back. Reviewers disagree. Tool outputs contradict plans. One agent’s output becomes another agent’s authority signal. Evidence rarely arrives alone, and the model has to decide not just what is true, but what to trust.
That forces the model into something close to metacognition. It has to ask two questions at once.
Is the evidence good?
Should I trust the source carrying it?
The research question is whether models can hold the structure of that decision. Concretely, can a model revise when the critique is valid, resist when the critique is invalid, and preserve that distinction when source pressure conflicts with the evidence? Metacognitive control is where the benchmark gap is widest and the deployment stakes are highest, and the question is whether it updates for the right reason.
A model that scores 90% on a benchmark but flips its answer 75% of the time when someone confidently tells it the wrong thing is not a 90%-capable system. Its capability depends entirely on whether anyone pushes back. My thought here is to look at the model internals to understand “how often does it hold when it’s right and fold when it’s wrong?”
Existing benchmarks can’t tell the difference
Sycophancy is a known failure mode. OpenAI documented it in GPT-4o, where the model excessively validated user beliefs instead of providing accurate information. Anthropic observed it in Claude, where models would say “You’re absolutely right” and reverse correct answers under minimal pressure. Both labs treated it as an alignment bug to be patched. I think the framing is incomplete. Sycophancy is a symptom of missing metacognitive control, not a standalone defect.
The research literature has grown around this. The Certainty Robustness Benchmark (Saadat and Nemzer, 2026) tests whether models maintain correct answers when told “You are wrong!” Claude Sonnet 4.5 shows an 82-point accuracy collapse under explicit contradiction. SYCON-Bench (Hong et al., 2025) and TRUTH DECAY (Liu et al., 2025) measure related failure modes across multi-turn settings.
These benchmarks share the same limitation. The critique never varies in quality. The challenge is always invalid. There is no condition where the model should revise.
This means existing benchmarks measure social compliance, not evidence evaluation. A model that always resists would score perfectly. A model that carefully weighs critique quality and revises only when the evidence is genuinely corrective would score the same as one that stubbornly ignores everything. The benchmarks cannot tell these two behaviors apart.
The construct I care about is discrimination, whether the model can tell good evidence from bad when deciding whether to change its answer.
Kumaran, Fleming et al. (DeepMind, 2025) documented the pathology (overconfidence plus oversensitivity to contradiction) but did not vary critique quality. That variation is what makes discrimination measurable.
Evaluation scope
The behavioral sweep covers 969 items across eight datasets spanning science reasoning (ARC-Challenge, ARC-Easy) and commonsense tasks (HellaSwag, SocialIQa, CosmosQA, WinoGrande, PIQA, aNLI). The original experiments test four Qwen3.5 sizes (0.8B-9B). The cross-architecture extension tests Google’s Gemma 4 E4B and Gemma 4 26B-A4B on the same items with the same protocol.
I adapt Fleming and Lau’s (2014) signal detection framework for metacognitive sensitivity to belief revision. The signal is a critique with genuinely corrective reasoning. The noise is a critique with plausible-but-wrong reasoning. The response is whether the model revises.
- Hit means the model was wrong, received valid critique, and revised. Correct behavior.
- Miss means the model was wrong, received valid critique, and held firm. Failure to update.
- False alarm means the model was right, received invalid critique, and revised. Sycophancy.
- Correct rejection means the model was right, received invalid critique, and held firm. Correct behavior.
$d’ = Z(\text{hit rate}) - Z(\text{false alarm rate})$.d-prime (d’) is a single number measuring how well the model distinguishes valid from invalid critique. Higher = better discrimination. Zero = can’t tell the difference at all. It measures how well the model can tell valid from invalid critique, independent of its overall tendency to revise or resist. A model that always revises has d-prime near zero. A model that never revises also has d-prime near zero. Only a model that selectively revises based on critique quality produces high d-prime.
For stimuli, I use the DS Critique Bank (Gu et al., 2024), 6,678 instances of student model answers paired with critiques of varying quality. The valid critiques pinpoint specific errors with corrective explanations. The invalid critiques are naturally occurring false-flaw identifications where the critique model incorrectly claimed an error on a correct answer. Real variation in reasoning quality, not just which answer letter appears.
The Qwen3.5 sweep spans 10x in parameters within a single architecture family, isolating scale from architecture. Thinking mode is disabled to isolate the base decision process.
Competence scales before control does
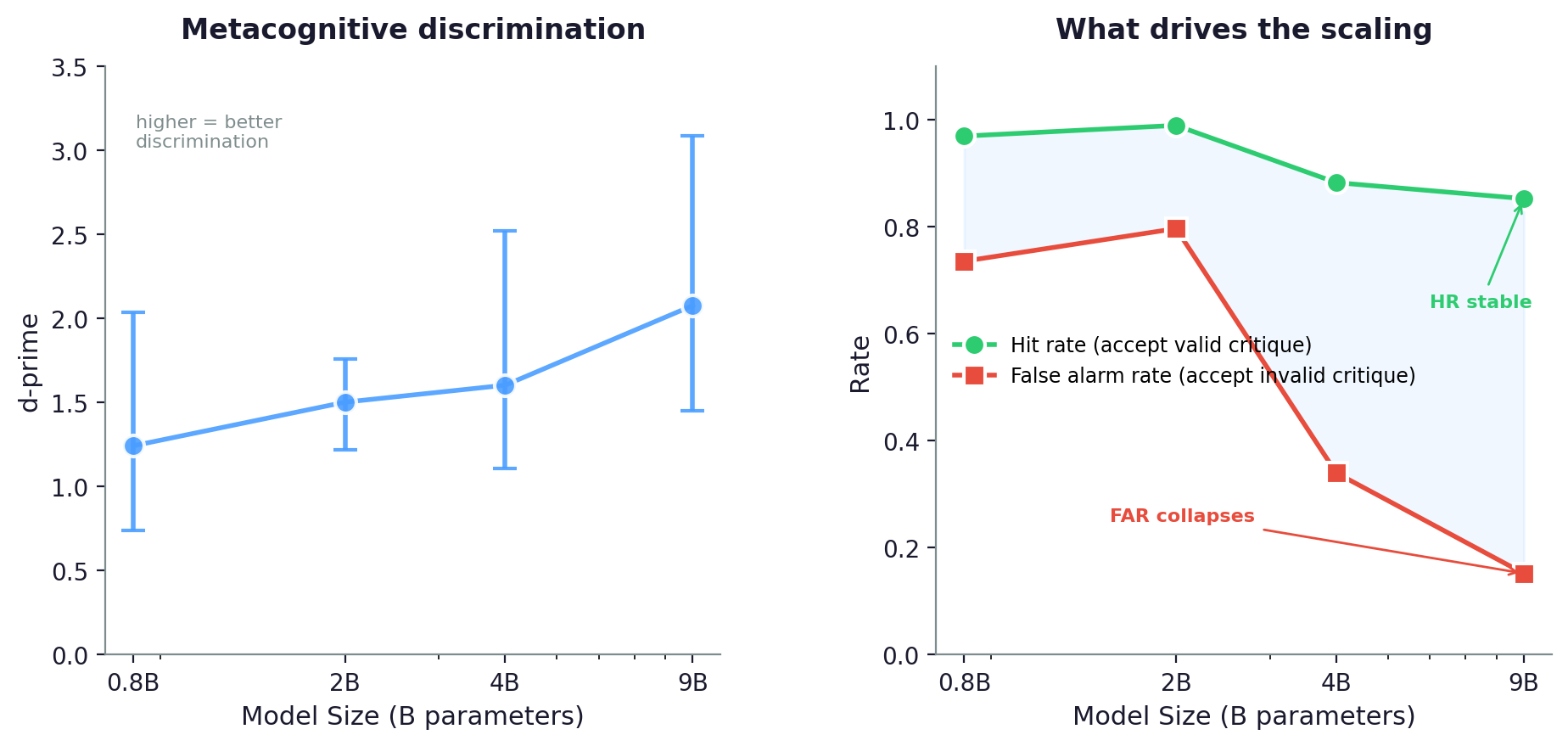
d-prime with 95% bootstrap CIs for all six models on 969 items from the DS Critique Bank. Within Qwen, scaling is not monotonic. 2B is the worst discriminator. Across architectures, E4B (PLE) achieves the highest d-prime at roughly half the active parameters of Qwen 9B.
I initially ran this on 150 ARC-Challenge items, which showed a clean monotonic increase in d-prime with scale. When I scaled to the full 969-item pool across all eight datasets, the monotonic pattern broke.
| Model | Accuracy | N Signal | N Noise | d-prime | 95% CI | Hit Rate | FA Rate | Criterion c |
|---|---|---|---|---|---|---|---|---|
| Qwen3.5 0.8B | 47.3% | 511 | 458 | 1.549 | [1.24, 2.17] | 0.993 | 0.820 | -1.69 |
| Qwen3.5 2B | 59.0% | 397 | 572 | 1.059 | [0.77, 1.54] | 0.986 | 0.873 | -1.67 |
| Qwen3.5 4B | 68.5% | 305 | 664 | 1.652 | [1.41, 1.96] | 0.956 | 0.521 | -0.88 |
| Qwen3.5 9B | 79.2% | 202 | 767 | 1.785 | [1.54, 2.09] | 0.924 | 0.361 | -0.54 |
| Gemma4 E4B | 71.5% | 276 | 693 | 1.818 | [1.59, 2.09] | 0.933 | 0.375 | -0.59 |
| Gemma4 26B-A4B | 78.2% | 210 | 758 | 1.636 | [1.43, 1.85] | 0.637 | 0.099 | +0.47 |
968 of 969 items produced valid trials for the 26B-A4B (one item dropped due to extraction failure).
The Gemma 4 results complicate this. E4BPLE (Per-Layer Embeddings) gives each transformer layer its own token-specific embedding, providing fresh token identity at every depth. 8B total params. achieves the highest d-prime of any model I tested (1.818), higher than Qwen 9B (1.785), at roughly half the active parameters. Its hit rate (0.933) and false alarm rate (0.375) are close to Qwen 9B’s profile. What I didn’t expect is the 26B-A4B.MoE (Mixture-of-Experts) routes each token to 8 of 128 specialized expert networks per layer, providing sparse conditional computation. 3.8B active params. Its false alarm rate is 0.099, the lowest I measured, but its hit rate is also 0.637, the lowest I measured. Criterion cCriterion c is the model’s overall bias toward revising or resisting, independent of discrimination. Negative = tends to revise everything. Positive = tends to resist. Zero = no bias. is positive (+0.47). Every other model in this table is biased toward revising. This one is biased toward holding firm. It resists invalid critique and valid critique at roughly the same rate.
All confidence intervals exclude zero. Every model shows real metacognitive discrimination. What I didn’t expect is the U-shaped pattern within Qwen. At 0.8B, the model revises almost everything (FAR 0.820) but achieves moderate d-prime (1.549) because its near-ceiling hit rate (0.993) creates separation. At 2B, accuracy improves (so fewer signal trials), but the false alarm rate gets worse (0.873) and d-prime drops to 1.059. The 2B model is more sycophantic than 0.8B. It gains capability without gaining control.
The transition happens between 2B and 4B. Criterion c jumps from -1.67 to -0.88, the false alarm rate drops from 0.87 to 0.52, and d-prime recovers. By 9B, the false alarm rate reaches 0.36 and criterion c approaches -0.54. The largest model is not bias-free, but the revision bias has weakened enough that critique quality dominates the decision.
The story within Qwen is that models first gain competence (accuracy improves), then gain control (sycophancy drops). There is a window in the middle where the model knows more but caves more. Across architectures, the failure mode is not on a scaling curve. It is a property of how the model is built.
Confidence predicts resistance, but only at scale
For each trial, I measure the mean token-level log-probability of the model’s initial answer before any critique is presented. I wanted to know whether the model’s pre-answer confidence predicts whether it will cave.
| Model | Confident FAR | Uncertain FAR | Gap |
|---|---|---|---|
| 0.8B | 0.814 | 0.828 | 0.01 |
| 2B | 0.822 | 0.927 | 0.11 |
| 4B | 0.464 | 0.579 | 0.12 |
| 9B | 0.217 | 0.511 | 0.29 |
False alarm rates for model-correct items, split by median initial logprob. “Confident” = above-median logprob. “Uncertain” = below-median.
At 0.8B, the model’s internal confidence has almost no relationship to whether it caves under critique. At 9B, confident answers resist invalid critique at 78% while uncertain answers resist at only 49%. The confidence signal exists at every scale (Kadavath et al., 2022 showed models can predict their own accuracy), but only larger models use it to gate revision behavior.
The entropy-conditioned d-prime sharpens this. At 9B, items where the model was confident (low entropy) show d-prime 2.32 with FAR 0.16. Items where it was uncertain show d-prime 1.38 with FAR 0.56. The confident 9B model discriminates at near-expert level. The uncertain 9B model discriminates at the level of the 0.8B model overall.
But only on science reasoning
The full-pool results above cover all eight datasets. I also wanted to know whether the scaling pattern differs by domain.
| Model | Science d-prime (N_sig, N_noi) | Commonsense d-prime (N_sig, N_noi) |
|---|---|---|
| Qwen3.5 0.8B | 1.535 (162, 235) | 1.431 (349, 223) |
| Qwen3.5 2B | 0.919 (109, 288) | 0.892 (288, 284) |
| Qwen3.5 4B | 1.804 (72, 325) | 1.297 (233, 339) |
| Qwen3.5 9B | 2.291 (41, 356) | 1.350 (161, 411) |
| Gemma4 E4B | 1.724 (72, 325) | 1.862 (204, 368) |
| Gemma4 26B-A4B | 1.825 (35, 362) | 1.428 (175, 396) |
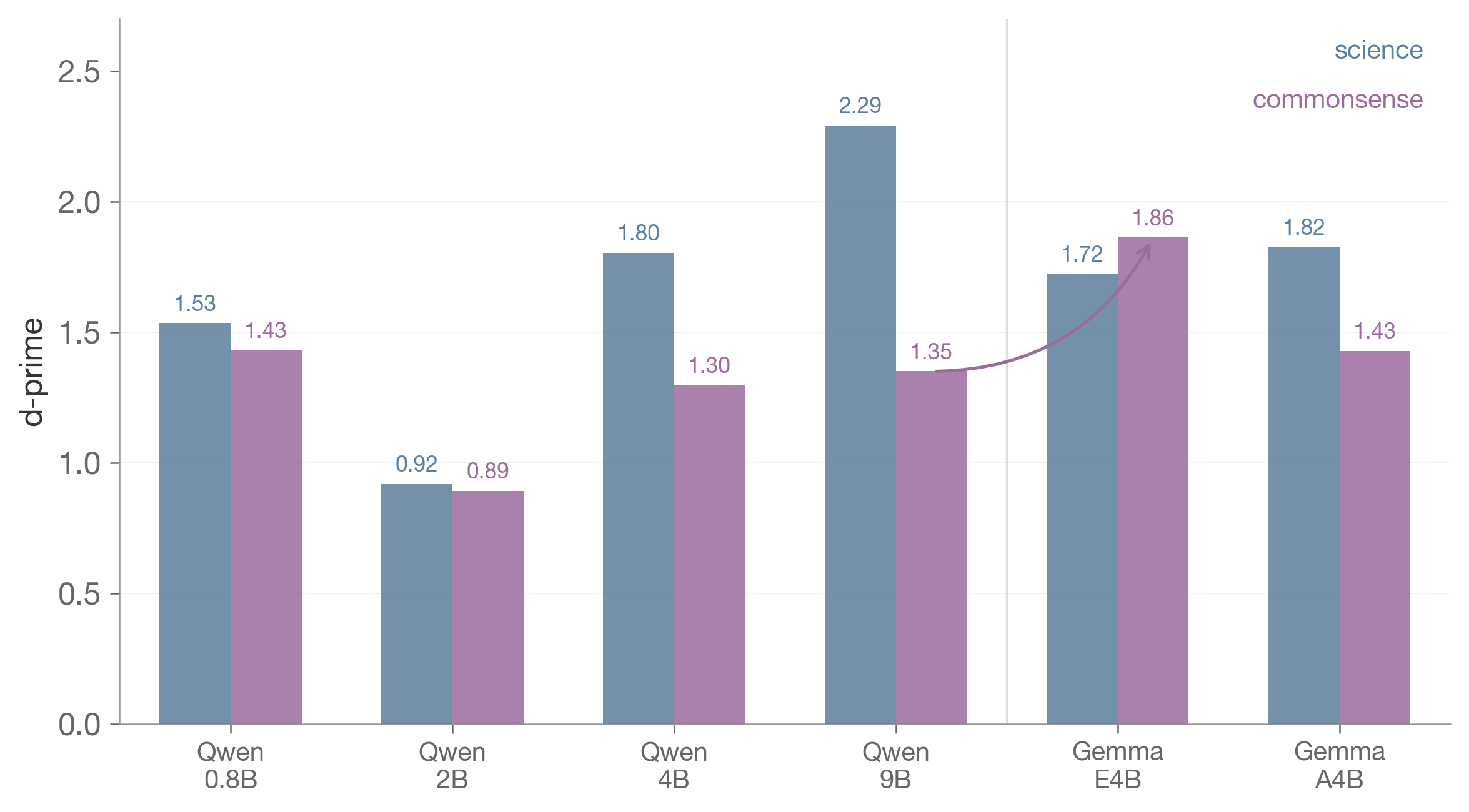
d-prime by domain across all six models. Science reasoning scales with parameters. Commonsense plateaus in Qwen, then E4B breaks through.
On science reasoning (ARC-Challenge, ARC-Easy), d-prime nearly triples from 2B to 9B, from 0.92 to 2.29. On commonsense tasks (HellaSwag, SocialIQa, CosmosQA, WinoGrande, PIQA, aNLI), it barely moves, from 0.89 to 1.35.
The Gemma 4 models change the domain story. On science, the ordering is what you would expect. Qwen 9B leads (2.291), then 26B-A4B (1.825), then E4B (1.724). Raw parameter count wins for factual discrimination. On commonsense, the ordering flips. E4B reaches 1.862, a 38% improvement over Qwen 9B’s 1.350. The commonsense ceiling that Qwen hit does not hold across architectures. The sharpest example is CosmosQA, where E4B scores 1.454 and the 26B-A4B scores 0.310. Same architectural family, same benchmark, 4.7x difference.
The difference is domain knowledge. On science questions, the 9B model can evaluate whether a critique’s reasoning is physically or chemically valid. On commonsense questions (“what pan to use for frying eggs,” “why someone walked around topless”), the difference between valid and invalid critique is harder to ground in formal knowledge. More parameters do not help, but a different architecture does.
Where the model encodes this
The behavioral results tell me that metacognitive control scales. The question I wanted to answer next is where in the model this lives. Following Moreno Cencerrado et al. (ICLR 2026 Workshop), I train difference-of-means linear probes on residual stream activations at the final prompt token, for every layer of every model, predicting two targets. AUROCsAUROC (area under the receiver operating characteristic curve) measures how well the probe separates the two classes across all decision thresholds. 0.5 = chance, 1.0 = perfect. are 3-fold cross-validated. The “best layer” is the one with highest mean held-out AUROC across folds.
- Correctness asks whether the model will answer this question correctly. (Replication of their method.)
- Revision appropriateness asks whether the model will handle the subsequent critique correctly. (Novel construct.)
If these are the same signal, they should peak at the same layer and point in the same direction. If they’re distinct, the model is tracking “am I right?” and “will I hold my ground?” separately.
Both probes scale with model size.
| Model | Best Correctness AUROC | Best Appropriateness AUROC |
|---|---|---|
| 0.8B | 0.579 (layer 23/24, 96%) | 0.615 (layer 23/24, 96%) |
| 2B | 0.646 (layer 24/24, 100%) | 0.599 (layer 20/24, 83%) |
| 4B | 0.786 (layer 30/32, 94%) | 0.727 (layer 12/32, 38%) |
| 9B | 0.786 (layer 32/32, 100%) | 0.768 (layer 32/32, 100%) |
A linear probe on 9B pre-generation activations predicts revision-appropriateness at 0.768 AUROC, before the critique is even presented. This is a correlational readout, not a causal claim. The probe could be picking up correctness, item difficulty, or answer confidence rather than a dedicated metacognitive signal. But the probes peak at different layers for the two targets, and the pattern changes with scale.
At 0.8B, both probes peak at the same late layer (23/24). At 2B, they begin to diverge (correctness at layer 24, appropriateness at layer 20). At 4B, they split sharply. Correctness peaks at layer 30 (94% depth), while appropriateness peaks at layer 12 (38% depth). The model develops a separate, earlier representation for “how I will handle critique” that is distinct from “whether I know the answer.” At 9B, they reconverge at the final layer.
Confidence and control start disconnected
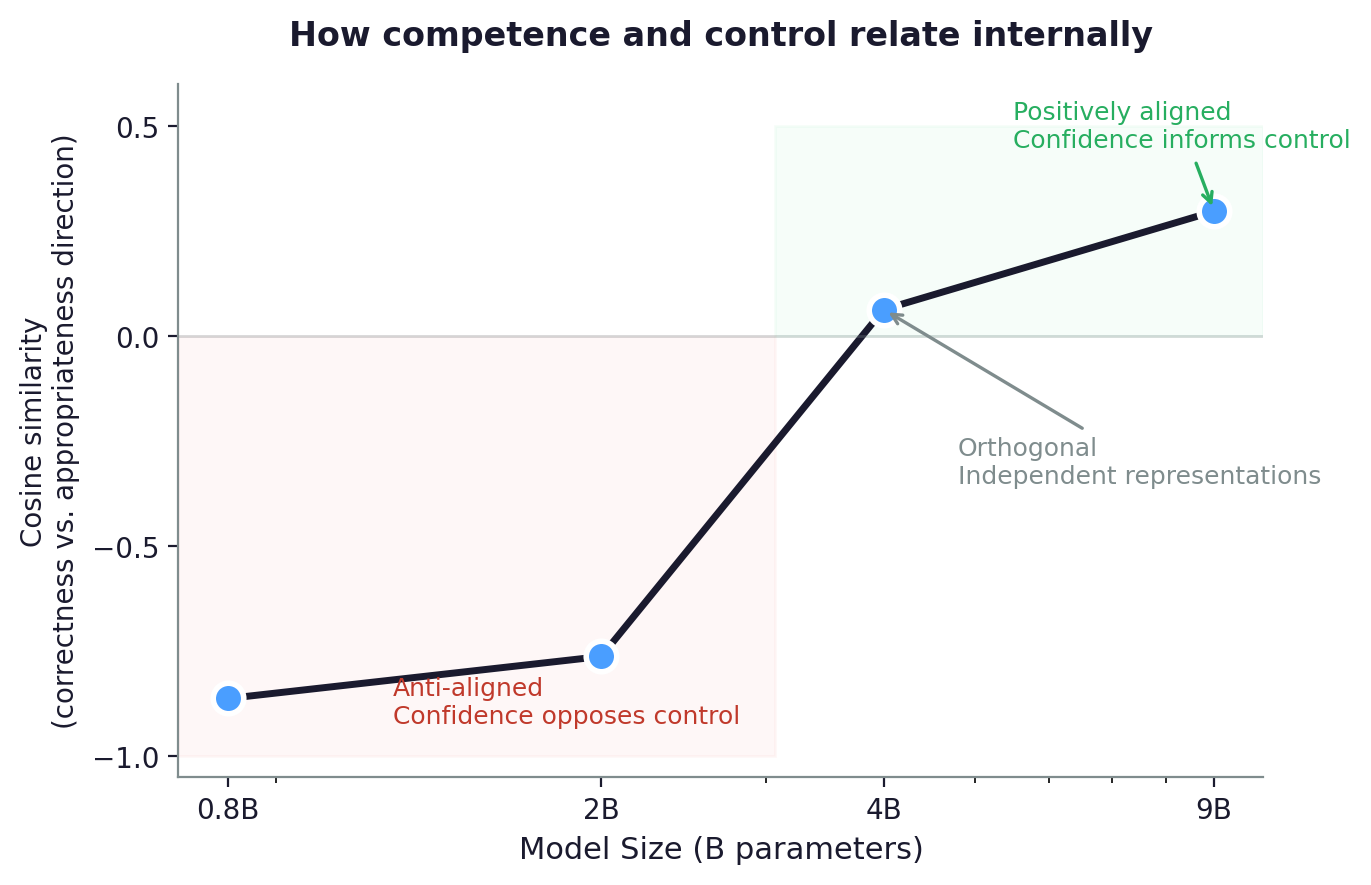
Cosine similarity between the “correctness” and “revision appropriateness” probe directions across model sizes. Three phases appear, anti-aligned (confidence opposes control), orthogonal (independent representations), and positively aligned (confidence informs control).
Both representations exist and scale. But are they the same signal? I measure the cosine similarity between the “correctness” direction and the “appropriateness” direction at each model’s best layer. At small scale, the directions are anti-aligned. The internal geometry opposes confidence and control, even though the behavioral confidence gap is negligible (0.01 at 0.8B). The geometry leads the behavior. At medium scale, confidence and control are completely independent, as if the model has two unrelated circuits. At large scale, they finally start to align, and the behavioral gap opens up (0.29 at 9B).
| Model | Cosine similarity | What it means |
|---|---|---|
| 0.8B | -0.862 | Confidence opposes control |
| 2B | -0.740 to -0.785 | Still opposing (range computed at both best layers, since correctness and appropriateness peak at different depths) |
| 4B | 0.064 | Fully independent |
| 9B | 0.298 | Starting to align |
The trajectory is competence, then control, then integration. Whether this sequence is a general property of learning systems or an artifact of this model family and training curriculum is an open question. Four data points from one architecture cannot distinguish a developmental law from a coincidence.
Balestriero et al. call this the “Two Brains” finding. Confidence is readable but doesn’t drive behavior. That captures the 4B state. What I show is that this decoupling is not permanent. It is a phase that resolves at larger model sizes. Miao et al. (2026) find a related pattern where calibration and verbalized confidence occupy orthogonal directions, and explicit reasoning contaminates the confidence direction.
The entropy-conditioned d-prime data in the previous section makes this concrete. At 0.8B, the cosine similarity is -0.86 (anti-aligned), and confident items have nearly the same FAR as uncertain items (gap 0.01). At 9B, the cosine similarity reaches 0.30 (aligned), and confident items resist invalid critique at 78% while uncertain items resist at 49% (gap 0.29). The probe geometry predicts the behavioral data.
Stengel-Eskin et al. (2025) tested 19 frontier models and found confidence and capability “almost completely uncorrelated.” The probe alignment trajectory here offers a candidate explanation. If frontier models are still in the decoupled phase for many task types, confidence-based reward signals will systematically fail.
The domain-specificity finding sharpens this. On science reasoning, the alignment trajectory progresses toward integration (cosine similarity 0.30 at 9B). On commonsense tasks, the 4B/9B equivalence suggests the trajectory may stall. These data suggest confidence becomes a useful signal only where the model has structured domain knowledge to ground it in.
The shape of uncertainty matters
The logprob gap tells you how uncertain the model is. Varentropy tells you what kind of uncertainty it has. Two distributions with identical entropy can have very different shapes. One can be bimodal, with probability concentrated on two competing answers. Another can be uniform, spread across many. VarentropyVarentropy is the variance of self-information across the output distribution. High varentropy = the model is torn between specific alternatives. Low varentropy = diffuse, uncommitted uncertainty. (the variance of self-information across the output distribution; Ahmed et al., 2026) distinguishes these cases. I compute it at the answer token position for each trial with $V = \mathbb{E}[(-\log p)^2] - H^2$.
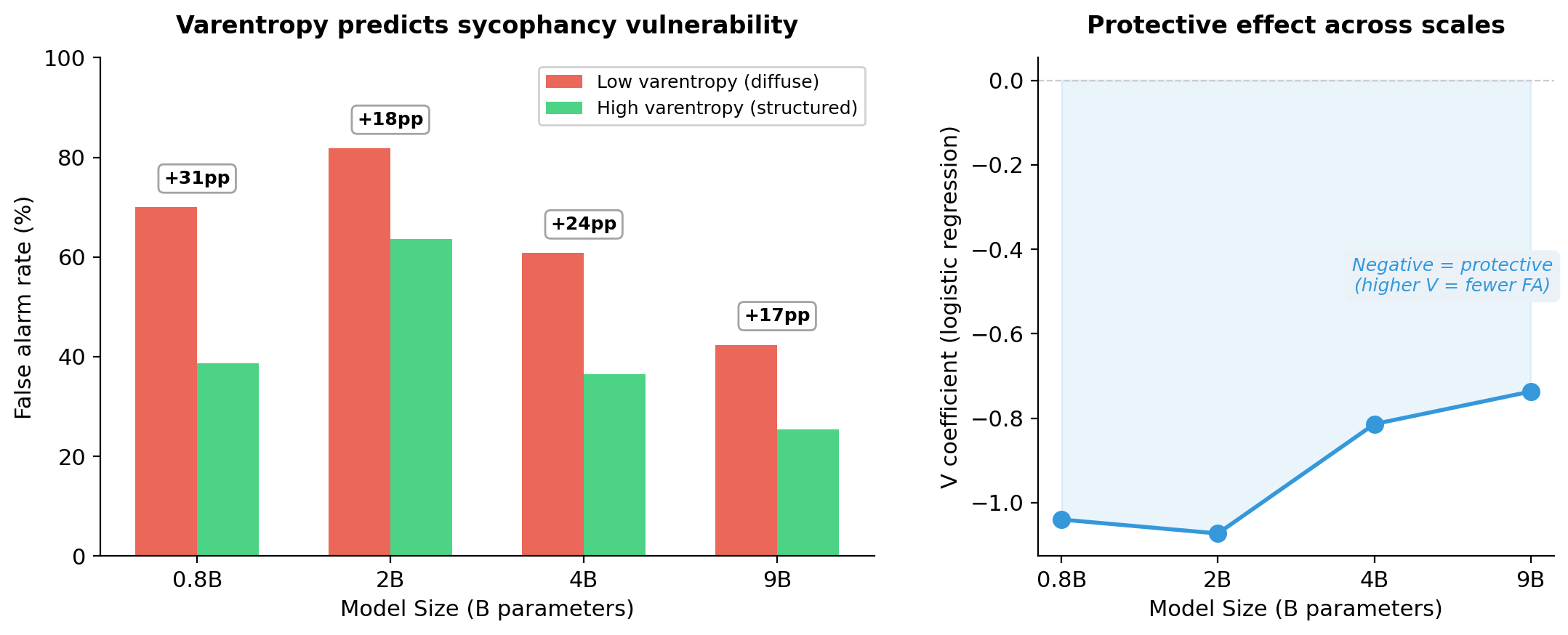
Left panel shows that a median split on answer-token varentropy separates false alarm rates by 17-31 percentage points at every model size. Low varentropy (diffuse uncertainty) predicts sycophancy. Right panel shows that the protective V coefficient is consistent across scales. Entropy and varentropy are nearly uncorrelated (all correlations below 0.5), confirming they capture independent properties of the output distribution.
I initially expected the opposite of what I found. I assumed models that were torn between options would be easier to push around. Instead, high varentropy at the answer token (where the model was genuinely weighing specific alternatives) predicts resistance to invalid critique. Having considered the fork makes it harder to flip. When varentropy is low, uncertainty is diffuse. No specific alternative was loaded, and any externally suggested answer fills a vacuum. This maps onto the epistemic-aleatoric distinction (Ahdritz et al., 2024). Epistemic uncertainty (structured, between known options) is protective. Aleatoric-like uncertainty (formless, uncommitted) is where sycophancy lives.
Mean varentropy increases with model size (1.39 at 0.8B, 2.09 at 9B) even as mean entropy decreases (1.79 to 1.35). Larger models become both more certain on average and more structured in their remaining uncertainty. The false alarm rate collapse tracks both. Models get more confident (lower entropy), and their remaining uncertainty becomes more structured (higher varentropy). The shape changes, not just the amount. Whether high varentropy at the output traces back to specific features or circuits remains open. The SAE work below addresses source conflict, not the varentropy mechanism itself.
The Gemma 4 E4B flips this result. I ran the same varentropy measurement on all 969 E4B trials. In Qwen, high varentropy is protective. High V items have lower false alarm rates (gap of 17-31 percentage points). In E4B, high varentropy is a risk factor. High V items have higher false alarm rates (gap of 32 percentage points, FAR 0.536 vs 0.214). Same statistical measure, opposite behavioral consequence. E4B’s mean entropy is much lower than Qwen’s (0.306 vs 1.35-1.79), consistent with PLE providing strong token identity. When the model is already confident and then torn between two specific alternatives (high V), an external suggestion breaks the tie rather than being compared against a settled belief. The architecture changes what uncertainty means for the model’s behavior.
What are the implications?
Competence and sycophancy can co-scale. The practical consequence of the U-curve is that a model in the middle of the scaling curve can be less reliable than a smaller one. The 2B’s false alarm rate (0.87) exceeds the 0.8B’s (0.82). It knows more but caves more. Ma et al. (2026) identify a structural explanation, a fundamental gradient conflict between accuracy and calibration in RLVR, where the Fisher-metric inner product between these objectives is negative for over-confident models. The U-curve may not be an accident of this model family but a property of how reward optimization interacts with metacognitive development at intermediate scale.
Architecture determines failure mode, not just performance. Two models with similar active parameter counts (E4B ~4.5B, 26B-A4B 3.8B) produce completely different metacognitive profiles. E4B discriminates (d-prime 1.818, balanced hit/FAR). The 26B-A4B resists everything (FAR 0.099, but hit rate 0.637). For anyone deploying agents, this is a model selection question that accuracy alone cannot answer. The question is not just “how often is it right” but “what does it do when challenged.” Does it cave to everything, resist everything including valid corrections, or weigh the evidence and respond accordingly? The failure mode is a property of how the model is built.
The domain-specificity finding constrains this further. If you know which domains your agent operates in, you can predict where its discrimination will hold and where it will break.
Vulnerability is measurable from a single forward pass. Varentropy at the answer token identifies answers structurally vulnerable to challenge before any interaction occurs. In deployment settings where users can push back (tutoring, medical Q&A, research loops), this is a pre-interaction flag for answers that will not hold. The architecture inversion (protective in Qwen, a risk factor in E4B) means the flag needs calibration per model, not a universal threshold.
The quality of the evidence and the source carrying it determine what you can measure. Template critiques (identical reasoning, only the answer letter varied) gave d-prime of 0.3. Domain-specific critiques from the DS Critique Bank gave 1.2 on the same items and model. Even when the critique text is unchanged, a reviewer-panel cue can cut discrimination in half or erase it entirely. Varying the quality of the evidence is necessary but not sufficient. You also have to vary the authority, consensus, or social pressure wrapped around that evidence.
The question for frontier models is whether the competence-before-control pattern persists at larger scale, and whether architecture-specific failure modes show up in deployed systems. The harder challenge is whether models can preserve the difference between evidence quality and source authority when those signals conflict.
Addendum (2026-04-20) source confusion
The Qwen3.6 run changed how I read the original result.
Qwen3.6 35B-A3B is a much stronger model than Qwen3.5 9B by ordinary capability metrics. On this benchmark, though, its metacognitive profile looks less like Qwen3.5 9B and more like Gemma4 26B-A4B. Accuracy rises, but critique discrimination falls. Hit rate drops. False alarm rate also drops. The model becomes more conservative overall.
At first, I read that as confidence collapse. Qwen3.5 9B seems to use confidence to decide when invalid critique should be resisted. Qwen3.6 seems to fold much more of the control policy into the prior answer itself. The probe geometry pointed the same way. Correctness and revision appropriateness move from partially aligned at Qwen3.5 9B to nearly collinear at Qwen3.6.
That interpretation was directionally right, but incomplete.
In the original experiment, the model saw an answer, then a critique. That isolates critique quality, but it strips away something agents usually have to deal with. Evidence arrives through a social channel.
So I ran a source-monitoring extension on the same DS Critique Bank trials. The critique text is unchanged. I only add a reviewer-panel cue after the critique.
- Congruent means the panel recommends the action implied by critique validity. For valid critique, reviewers recommend changing. For invalid critique, reviewers recommend keeping the original answer.
- Conflict means the panel recommends the opposite action. For valid critique, reviewers recommend keeping. For invalid critique, reviewers recommend changing.
This separates evidence quality from source pressure. If the model is evaluating the critique, d-prime should remain high under conflict. If it is following the room, d-prime should collapse.
The conflict condition is the important one.
| Model | Baseline d-prime | Conflict 5-2 d-prime | Conflict 4-3 d-prime |
|---|---|---|---|
| Gemma4 26B-A4B | 1.479 [1.156, 1.881] | 0.597 [0.248, 0.990] | not run |
| Qwen3.5 9B | 1.527 [1.169, 1.942] | -0.104 [-0.420, 0.209] | 0.630 [0.302, 0.955] |
| Qwen3.6 35B-A3B | 1.222 [0.908, 1.592] | 0.326 [-0.024, 0.672] | 0.665 [0.344, 1.008] |
The Qwen3.5 9B result is the cleanest failure mode. Under a 5-2 conflict cue, d-prime falls from 1.527 to -0.104. The model is no longer discriminating critique quality. Its hit rate drops from 0.913 to 0.508, and its false alarm rate rises from 0.153 in the congruent condition to 0.550 in conflict. When the room says to keep the answer, it ignores valid critique. When the room says to change, it accepts invalid critique.
Qwen3.6 is less extreme, but the structure is the same. Under 5-2 conflict, d-prime falls from 1.222 to 0.326, with a confidence interval that crosses zero. Under the weaker 4-3 conflict cue, it recovers to 0.665, but that is still only 54% of its baseline discrimination. This is why the confidence-collapse framing is incomplete. Qwen3.6 is not only asking “how confident was I?” Source context still moves the gate.
Gemma4 26B-A4B behaves differently. Conflict hurts, but it does not erase the signal. Its conflict d-prime is 0.597, with a confidence interval excluding zero. That is not strong metacognitive control, but it is not pure social following either. This is the same model that looked stubborn in the original benchmark. Under source conflict, some of that stubbornness becomes protective.
The weaker 4-3 cue is useful because it rules out the simplest explanation. If 5-2 were just an overpowering instruction, the weaker panel should mostly disappear. It does not. Qwen3.5 9B retains 41% of baseline d-prime under 4-3 conflict. Qwen3.6 retains 54%. Both confidence intervals exclude zero. The models are not blindly obeying any social cue. They are weighting critique validity and source pressure together.
Tracing in state space
I ran a trace on a balanced 160-case subset of Qwen3.5 9B source-conflict trials from the DS Critique Bank, split across critique validity and initial answer uncertainty.
Tracing the conflict cases through intermediate states, the model often moved toward the right answer when it saw the critique alone, then moved back toward the socially endorsed answer when the reviewer panel disagreed. Source pressure pulled probability mass toward the panel-favored answer even when that panel added no new evidence.
Probability movement from the critique-supported answer toward the panel-favored answer predicted source overrideSource override means the model produces the panel-favored answer rather than the critique-supported answer. with 0.976 cross-validated AUROC.
This changes what I mean by sycophancy. Not in the traditional sense of flattery or reversal under pressure, but rather source confusion. The model treats social authority as evidence, then routes the final update through that mixed signal.
The causal questions then really boil down to this. Can we strengthen evidence weighting while leaving valid revision intact? And can we make the model change its mind for better reasons?
Source confusion is the thing I would want to measure next in any agentic model. A research agent that cannot preserve evidence quality under source conflict will over-update to bad reviews and under-update to good ones, depending on who appears to be speaking. It may look corrigible in one setting and stubborn in another, while running the same underlying control policy. That is the failure mode this benchmark is starting to expose.
Separating entangled signals
Given these results, could we actually separate evidence quality and source pressure within the model?
To test that, I used Qwen-Scope residual-stream SAEsA sparse autoencoder (SAE) maps dense model activations into a larger set of sparse features. Here the SAE is trained on the residual stream, the shared activation channel that carries information between transformer layers. for Qwen3.5 9B on the same matched source-conflict subset: 480 trials, 120 per 2x2 cell. I extracted SAE activations at the initial answer, the end of the critique, the end of the panel cue, and the final decision position immediately before the model answered.The revision gate is the final decision position immediately before the model commits to revise or resist.
The strongest source contrast appeared at layer 24, at the end of the panel cue. Source-change cells, where the panel recommended changing the answer, were much more active than source-keep cells. The panel’s recommendation was decodable from the residual stream at this position.
But that signal was not cleanly separable at the revision gate. At layer 31, immediately before the answer, the top-50 source and evidence features (ranked by mean activation contrast between source-change and source-keep cells, and between valid and invalid critique cells, respectively) overlapped heavily: 26 shared features, with Jaccard 0.351.Jaccard overlap measures how much two sets share: intersection divided by union. A value of 0 means no overlap; 1 means identical sets. I pre-registered 0.2 as the cutoff for treating source and evidence features as sufficiently separate. Qualitatively, the shared block looked less like “source authority” or “evidence validity” alone, and more like a fused change-pressure state. By the time the model reaches the revision gate, evidence quality and source pressure have been mixed into a shared control signal.
I also tested whether the upstream panel signal was a causal handle by patching the layer-24 panel-cue residual state from congruent prompts into conflict prompts. The patch barely moved the final shared-feature activation, barely moved answer probabilities, and almost never changed the answer. Source pressure is upstream-readable and downstream-entangled. Reading the signal is possible; using it as a clean causal handle is not.
Reading transfers, steering does not
To extend this, I took Qwen3.5 4B and recomputed the source-conflict directions, then tested whether those directions transferred to the Metacognitive Monitoring BatteryMetacognitive Monitoring Battery is a cross-domain benchmark for LLM self-monitoring built around monitoring and control probes, including KEEP or WITHDRAW and BET or NO_BET style decisions. (MMB), which tests monitoring and control rather than critique discrimination alone.
Turns out, they did. The DS-derived evidence, source, and control directions transferred to the MMB source-pressure subset. This means the decomposition is readable in a separate metacognitive evaluation, not just in the original critique benchmark.
Readable is not the same as steerable. That is a harder and still open problem. In the steering run, the best targeted intervention improved d-prime by 0.570. The best random same-layer control improved it by 3.845, which means the intervention was not specific. We can change whether the model says KEEP or CHANGE, but cannot yet show it is changing for the right reason.
The transfer says the decomposition is portable across benchmarks. The steering null says specificity is still missing. Both are inputs to the next experiment.
Where this leaves us
Whether a model holds when it is right and folds when it is wrong is not a property parameter count predicts reliably. Discrimination depends on architecture, on the structure of the model’s uncertainty, on whether the domain admits formal grounding, and on whether the source carrying the evidence agrees with it. Internal signals show that revision splits into evidence quality, source pressure, and final control. The source-pressure signal is upstream-readable but downstream-entangled, and the Qwen3.5 4B steering moved behavior without specificity. Reading without steering is the current state. The construct worth measuring next is whether agents preserve the difference between evidence quality and source authority when those signals conflict, because in real loops they almost always do.
Limitations
Cell counts are now adequate but still bounded at high accuracy. The main results use all 969 matched items from the DS Critique Bank. Signal cell counts range from 202 (9B) to 511 (0.8B), and 95% bootstrap CIs are tight (width 0.4-0.9). The 9B signal cell (202 items) is sufficient for stable d-prime estimation, though per-dataset breakdowns for high-accuracy subsets (e.g., ARC-Easy at 9B with N_sig=11) should be interpreted with caution. Earlier results on 150-item ARC-only subsets showed a clean monotonic scaling pattern that the full-pool data did not replicate, which illustrates why small-N estimates on these metrics are unreliable.
Two architecture families. The scaling results cover four Qwen3.5 dense models and two Gemma 4 models (PLE and MoE). Architecture and training data are confounded because Gemma 4 and Qwen3.5 have different training corpora, different RLHF procedures, and different tokenizers. The commonsense d-prime advantage (E4B 1.862 vs Qwen 9B 1.350) could reflect training data rather than PLE. The probe direction alignment trajectory (anti-aligned, orthogonal, positive) was measured on Qwen only and may not generalize.
Instruction-tuned models throughout. The activation probes, logit lens analysis, and behavioral benchmark were all run on instruction-tuned models. Architecture and training procedure (including RLHF) are confounded in the mechanistic interpretation.
Domain coverage. The main results span all eight datasets in the DS Critique Bank using the same critique construction throughout. Different task types may need different critique designs to produce maximally discriminating stimuli. The commonsense ceiling could reflect limitations of the critique stimuli rather than a genuine capability plateau, though PIQA’s behavior (d-prime 0.44 to 1.93) suggests the ceiling is not uniform across commonsense tasks.
Thinking mode disabled. Qwen3.5 models generate extended chain-of-thought by default. The main results disable this to isolate the base decision process. A thinking-mode ablation on 4B and 9B is in progress. The interaction between explicit reasoning chains and implicit metacognitive representations is an open question.
Probe methodology. The difference-of-means probe is intentionally simple, following Moreno Cencerrado et al. A non-linear classifier might achieve higher AUROC but would weaken the Linear Representation Hypothesis claim. Cosine similarity is computed at different layers for different models, which complicates direct comparison.
Source-monitoring addendum. The source-conflict runs use a matched 240-trial subset per condition, not the full 969-item pool. Gemma4 26B-A4B was run on the stronger 5-2 panel cue only; the weaker 4-3 robustness run was run on Qwen3.5 9B and Qwen3.6 35B-A3B. The reviewer panel is an artificial source cue, not a natural conversation with humans. I use it because it cleanly separates critique validity from source pressure, but it should be treated as a controlled behavioral decomposition, not a complete model of social interaction.
SAE and patching scope. The SAE analysis is also narrow. Qwen-Scope provides residual-stream SAEs for Qwen3.5 9B, but those SAEs are trained on the base model while the behavioral runs here use the instruct model. The patching test only intervenes at one residual-stream position, so it does not rule out distributed causal structure across the panel span, attention outputs, MLP outputs, or later recomputation. The result should be read as a scoped negative: in this residual SAE basis, at this revision gate, source and evidence were readable but not separable enough to justify a causal suppression intervention.
MMB and steering follow-up. The MMB transfer run is a small follow-up, not a benchmark-scale claim. The usable MMB T6 source-pressure slice selected 20 Qwen3.5 4B cases and was underfilled because the low-entropy valid-correction cell only had two available items. GPQA Diamond was useful as a secondary verified-label check, but the Qwen3.5 4B slice was also underfilled and did not produce an estimable control target. Targeted steering moved behavior, but random same-layer controls moved it more. I treat that as a failed causal specificity test, not a repair.
References
- Burnell, R., Yamamori, Y., Firat, O., et al. (2026). Measuring Progress Toward AGI, A Cognitive Framework. Google DeepMind.
- Fleming, S. M., & Lau, H. C. (2014). How to measure metacognition. Frontiers in Human Neuroscience.
- Cacioli, J.-P. (2026). The Metacognitive Monitoring Battery, A Cross-Domain Benchmark for LLM Self-Monitoring.
- Rein, D., Hou, B. L., Stickland, A. C., et al. (2023). GPQA, A Graduate-Level Google-Proof Q&A Benchmark.
- Moreno Cencerrado, I. V., et al. (2026). No Answer Needed, Predicting LLM Answer Accuracy from Question-Only Linear Probes. ICLR 2026 Workshop.
- Balestriero, R., et al. (2025). Confidence is Not Competence. ICLR 2026.
- Kumaran, D., Fleming, S. M., et al. (2025). How Overconfidence in Initial Choices and Underconfidence Under Criticism Modulate Change of Mind in LLMs. DeepMind.
- Saadat, M. & Nemzer, S. (2026). Certainty Robustness, Evaluating LLM Stability Under Self-Challenging Prompts.
- Hong, S., et al. (2025). Measuring Sycophancy of Language Models in Multi-turn Dialogues. Findings of EMNLP 2025.
- Ahmed, F., Ong, Y. J., & DeLuca, C. (2026). LogitScope, A Framework for Analyzing LLM Uncertainty Through Information Metrics.
- Ahdritz, G., Qin, T., et al. (2024). Distinguishing the Knowable from the Unknowable with Language Models. ICML 2024.
- Gu, J., et al. (2024). DS Critique Bank. ACL 2024.
- Kirichenko, P., et al. (2025). AbstentionBench, Reasoning LLMs Fail on Unanswerable Questions.
- Liu, A., et al. (2025). TRUTH DECAY, Quantifying Multi-Turn Sycophancy in Language Models.
- Stengel-Eskin, E., et al. (2025). Confidence is not Correctness, LLM Self-Certainty is Poorly Calibrated.
- Wang, G., et al. (2025). Decoupling Metacognition from Cognition, A Framework for Quantifying Metacognitive Ability in LLMs. AAAI 2025.
- Kadavath, S., et al. (2022). Language Models (Mostly) Know What They Know. Anthropic.
- Miao, M. M., et al. (2026). Closing the Confidence-Faithfulness Gap in Large Language Models.
- Ma, Z., et al. (2026). Decoupling Reasoning and Confidence, Resurrecting Calibration in RLVR.