Where should test-time compute go? Surprisal-guided selection in verifiable environments
TL;DR Given a capable model, how should you spend test-time compute? I tested three strategies on GPU kernel optimization: more training (worse than random), more samples (saturates at K=16), or smarter selection. Selecting the model’s least confident correct solution achieves 80% vs 50% for most-confident. Selecting the top 3 by surprisal matches oracle at 100%, with zero additional compute. The probability distribution maps frequency, not quality.
- Where should test-time compute go?
- GPU kernel optimization as testbed
- What I ran
- Selecting by surprisal
- Why not just train more?
- When this works and when it doesn’t
- What to do with this
- Can you skip evaluation with surprisal?
- What this doesn’t cover
- Try it yourself
- Resources
- Citation
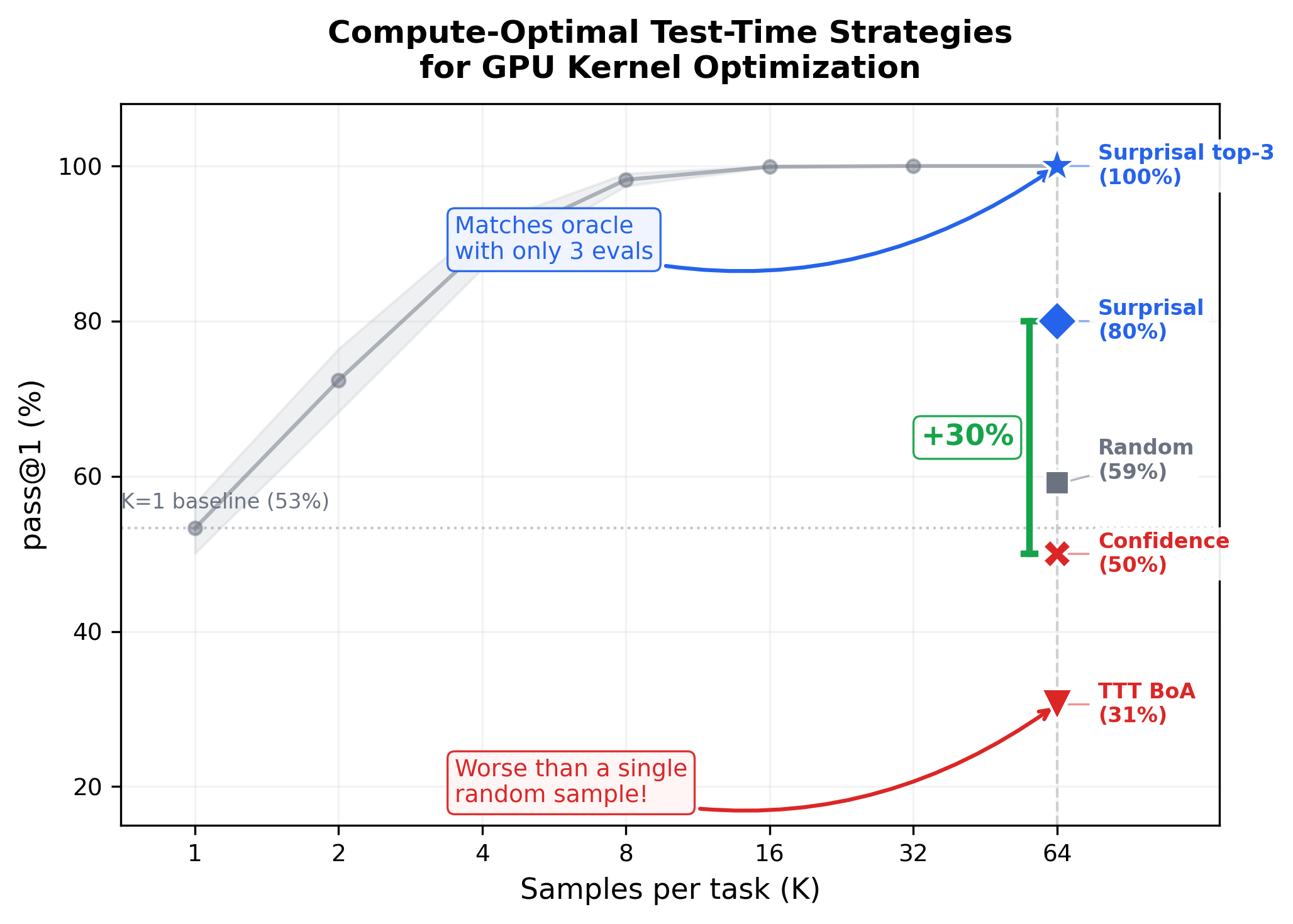
Best-of-N search saturates at K=16. Test-time training (TTT) adaptation (red) falls below K=1 random sampling. Surprisal-guided selection (blue) matches oracle at 100% by evaluating just 3 samples.
Where should test-time compute go?
Test-time adaptation shows strong results on reasoning and discovery tasks. TTT-Discover uses ~50 gradient steps to push past what base models can achieve. The practical question: does this generalize when the reward signal is dense and continuous? I tested on GPU kernel optimization to find out.
Given a capable code-generation model, three options: more training (gradient adaptation), more samples (search), or smarter selection.
I tested all three on GPU kernel optimization using KernelBench and a 120B-parameter model. The answer was decisive. More training: worse than random. TTT’s best checkpoint (30.6%, 3-seed mean) falls below a single random sample (53.3%). More samples: saturates fast. Best-of-N hits 99.9% at K=16. Smarter selection: matches oracle. Surprisal-guided-top3 achieves 100% by evaluating 3 candidates instead of 64.
GPU kernel optimization as testbed
KernelBench evaluates 250 GPU kernel optimization tasks. Given a PyTorch operation, the model generates an efficient CUDA kernel. The compiler and hardware provide ground-truth feedback: functional correctness and continuous speedup (0x to 10x+). No human judgment. I evaluate on all 20 KernelBench L1 eval tasks using GPT-OSS-120B with LoRA adaptation.
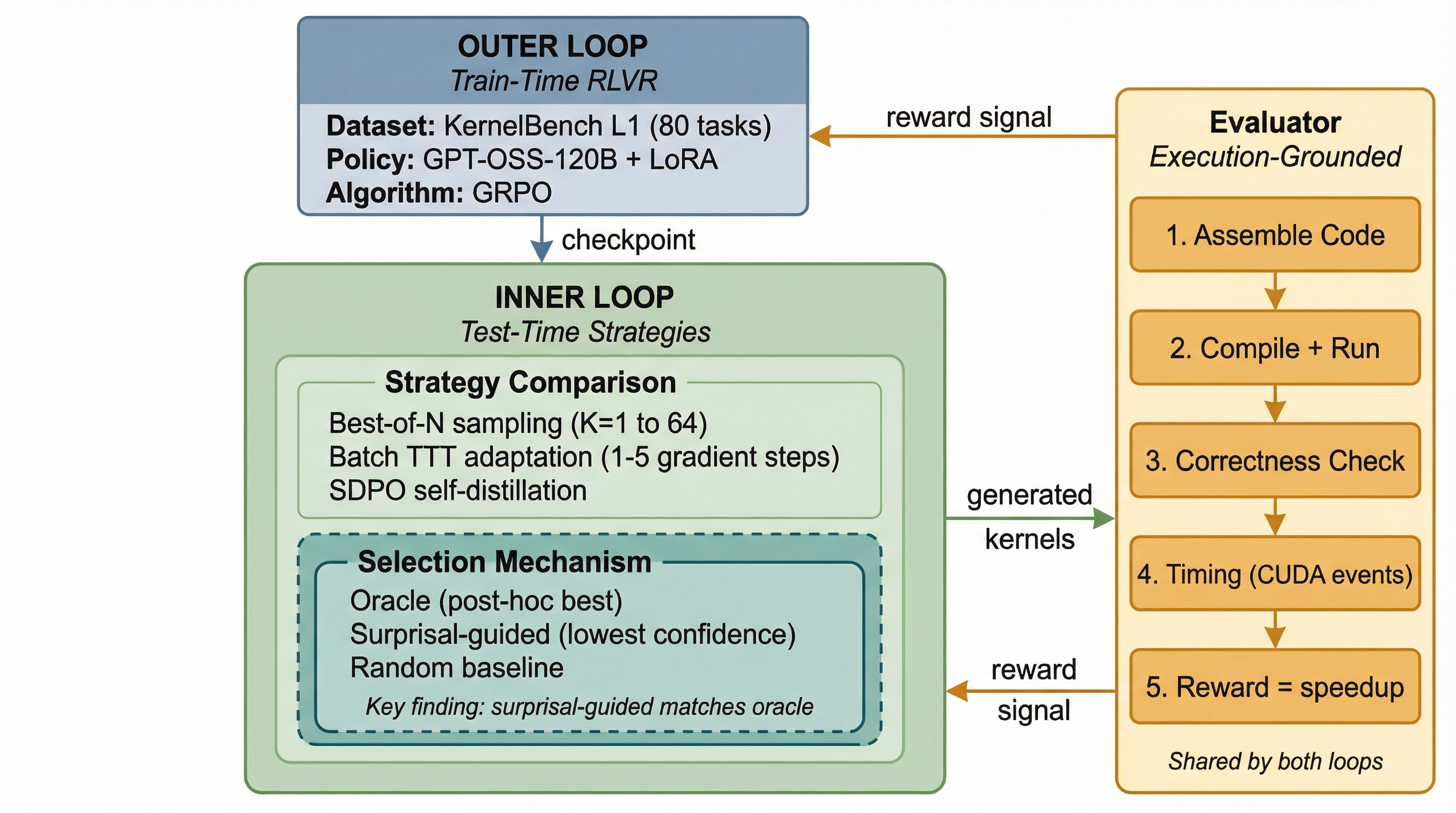
Dual-loop architecture. The outer loop trains a base policy via reinforcement learning with verifiable rewards (RLVR) on 80 tasks. The inner loop compares test-time strategies (TTT, Best-of-N, and selection mechanisms) under matched compute budgets against the same execution-grounded evaluator.
What I ran
I train a base policy using Group Relative Policy Optimization (GRPO) on 80 KernelBench L1 tasks with LoRA.LoRA (Low-Rank Adaptation): a parameter-efficient fine-tuning method that trains small rank-decomposed matrices instead of full model weights. Cuts trainable parameters by ~100x. The checkpoint achieves 98.4% correctness and 0.87x mean speedup, a capable starting point. At test time, I compare strategies under matched budgets: 320 rollouts, same temperature (0.25), same checkpoint.
Best-of-N (K=64): Sample 64 candidates per task, select the fastest correct one.
Batch TTT: Take 1-5 gradient steps, 32 rollouts per task per step. Select the best checkpoint via Best-of-Adaptation (BoA).
Selection strategies: Given K=64 samples per task, compare oracle, random, confidence-guided (highest log-probability), and surprisal-guided (lowest log-probability) selection.
Selecting by surprisal
I measure fast_1: the fraction of selected samples that are both correct and achieve speedup > 1x over the reference implementation.
| Strategy | fast_1 | std | Mean Speedup |
|---|---|---|---|
| Oracle (best correct) | 100% | 0% | 226.9x |
| Surprisal-guided-top3 | 100% | 0% | 139.0x |
| Surprisal-guided | 80% | 0% | 41.2x |
| Random correct | 59.2% | 2.7% | 30.0x |
| Confidence-guided | 50% | 14.1% | 11.6x |
Selection strategy comparison (Subset 1, 2 seeds). fast_1 = fraction of samples that are both correct and achieve speedup > 1x.
Surprisal-guided beats confidence-guided by 30 percentage points (80% vs 50%, Cohen’s h = 0.64).Cohen’s h: an effect size for comparing two proportions. 0.2 = small, 0.5 = medium, 0.8 = large. Evaluating the 3 highest-surprisal correct samples and picking the fastest matches oracle at 100%. Surprisal is the sequence-level sum of token log-probabilities, already produced during generation. No additional inference cost.
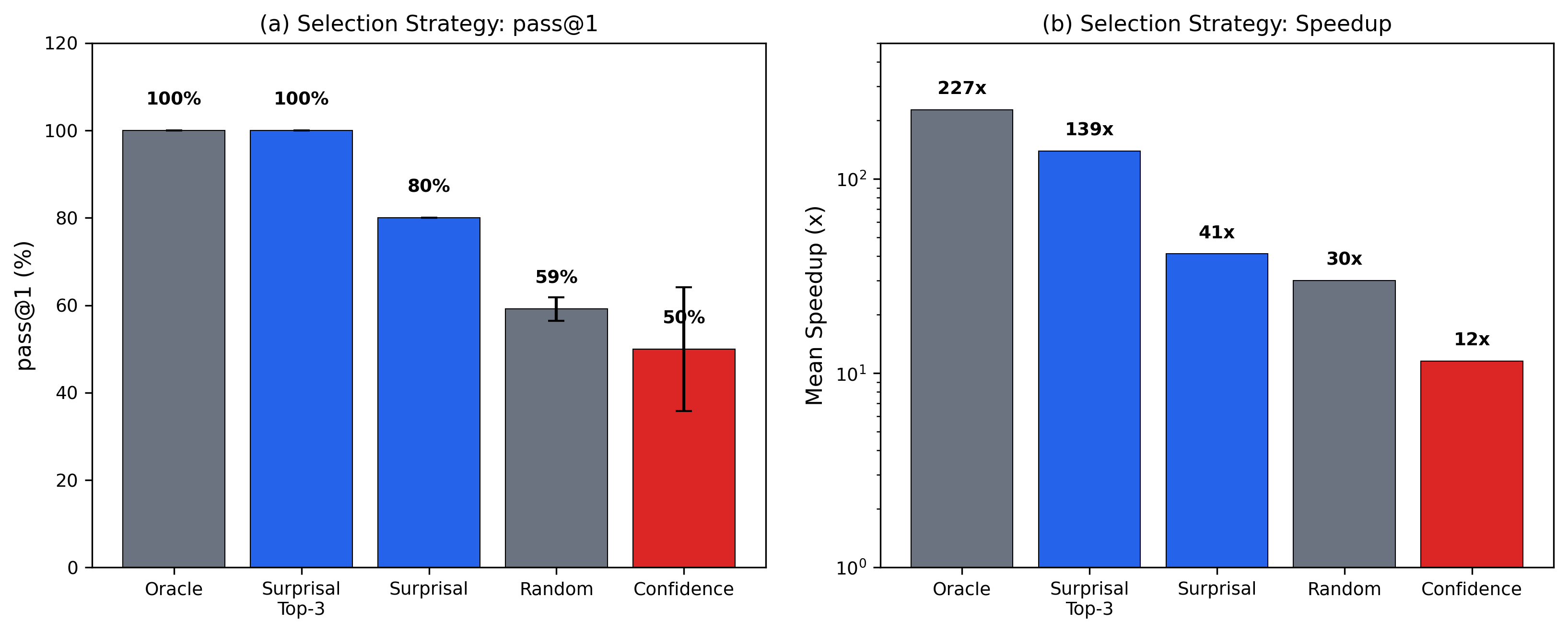
Surprisal-guided (blue) vs confidence-guided (red). The gap is consistent across seeds. Confidence-guided std = 14.1%; surprisal-guided std = 0%.
A distinction worth flagging: I select the most surprising correct sample, not the most surprising overall. Without the correctness filter, the highest-surprisal output would be gibberish. The execution-grounded setting provides that filter for free.
Why does this work? The model’s probability distribution maps frequency, not quality. Naive CUDA code is common in training data; expert-level hardware-optimized kernels are rare. The model’s “confidence” tells you how common a strategy is, not how fast it runs.
High-quality kernels require unusual memory access patterns, creative loop structures, and hardware-specific tricks that are underrepresented in pretraining. These solutions occupy what I call the Expert Tail: rare, high-performance strategies the model knows how to generate but considers statistically unlikely. That knowledge is already encoded in the logprobs. Unlike S* (Li et al., 2025), which requires additional LLM calls to differentiate candidates, surprisal-guided selection recovers the Expert Tail at zero cost.
I controlled for a potential confound: longer code has lower log-probability from accumulating more tokens. The partial correlation controlling for code length is zero (rho = 0.003, p = 0.95). The surprisal effect is not a length artifact.
A subtlety: near-zero global correlation seems to contradict the 80% vs 50% selection result. It doesn’t. Correlation measures whether surprisal linearly predicts speedup across all 550 correct samples, and it does not. Selection operates differently: for each task, pick the single highest-surprisal correct sample. This is a per-task argmax in the tail, not a global slope. The method succeeds when the highest-surprisal sample within each task tends to be among its best solutions, a per-task ordinal property that global linear correlation cannot capture.
The quartile breakdown confirms the shape. Q2 (second-highest surprisal) shows the highest fast_1 at 81.0%; Q4 (lowest surprisal) shows the lowest at 43.9%. The optimal selection point is in the high-surprisal region but not the extreme tail.
Why not just train more?
I started this project expecting TTT to help. It doesn’t.
Best-of-N at K=64 achieves 90% task success (18/20 L1 eval tasks). The 2 failures are informative: Task 82 achieves 100% correctness but 1.00x speedup (the reference uses cuDNN, leaving no optimization headroom); Task 95 achieves 0% correctness (model capability gap). Neither is a search strategy limitation. TTT’s best checkpoint reaches 30.6% (3-seed mean). On the scaling curve, that falls below K=1. Test-time training is worse than drawing a single random sample.
| Method | fast_1 | Equivalent K |
|---|---|---|
| Best-of-N K=64 | 100% | 64 |
| Best-of-N K=1 | 53.3% | 1 |
| TTT BoA (3-seed mean) | 30.6% | < 1 |
Subset 1 (5 tasks). Best-of-N achieves 90% (18/20) on the full L1 eval set.
The failure mode is over-sharpening. I probed this directly by scoring 320 fixed Best-of-N samples under each TTT checkpoint. The Spearman rho between negative log-likelihood (NLL)NLL (negative log-likelihood): how surprised the model is by a token sequence. Lower NLL = higher confidence. and speedup deepens from -0.198 (step 0) to -0.275 (step 8). In the bottom quartile (the tail where selection operates), rho nearly doubles from -0.24 to -0.44.
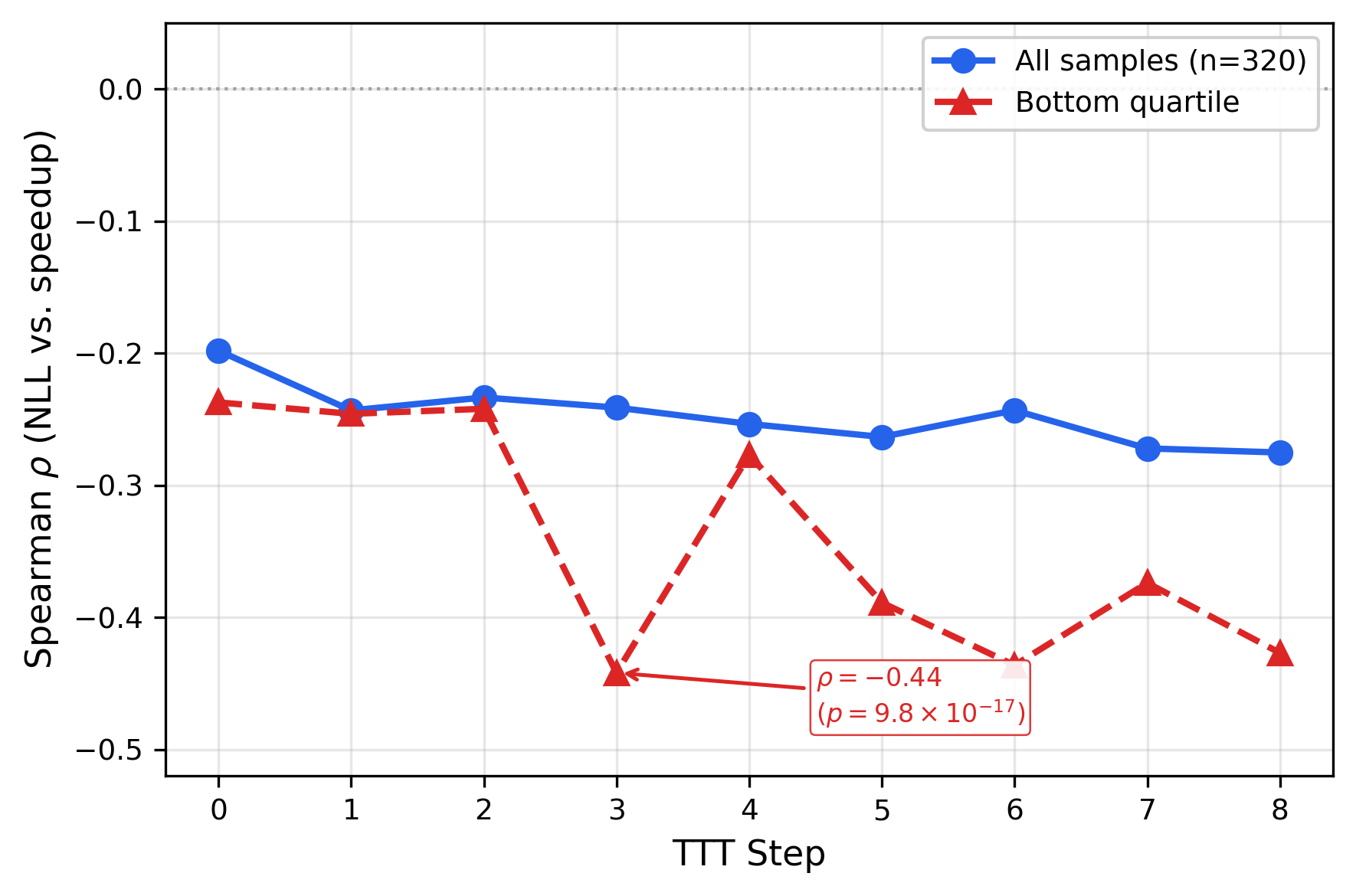
Adaptation makes the model progressively more confident about its worst solutions. Bottom-quartile correlation nearly doubles from -0.24 to -0.44.
Active anti-calibration: the model assigns higher confidence to worse solutions in exactly the region where surprisal-guided selection operates. Gradient updates collapse probability toward mediocre early successes, destroying the expert tail where optimal kernels live.
Cross-subset transfer confirms this is over-fitting, not under-training. Checkpoints adapted on Subset 1 and evaluated on Subset 2 achieve 7.5% fast_1, down from the unadapted baseline of 17.5%. Both transfer directions degrade. Adaptation memorizes training-subset modes rather than learning generalizable kernel optimization strategies.
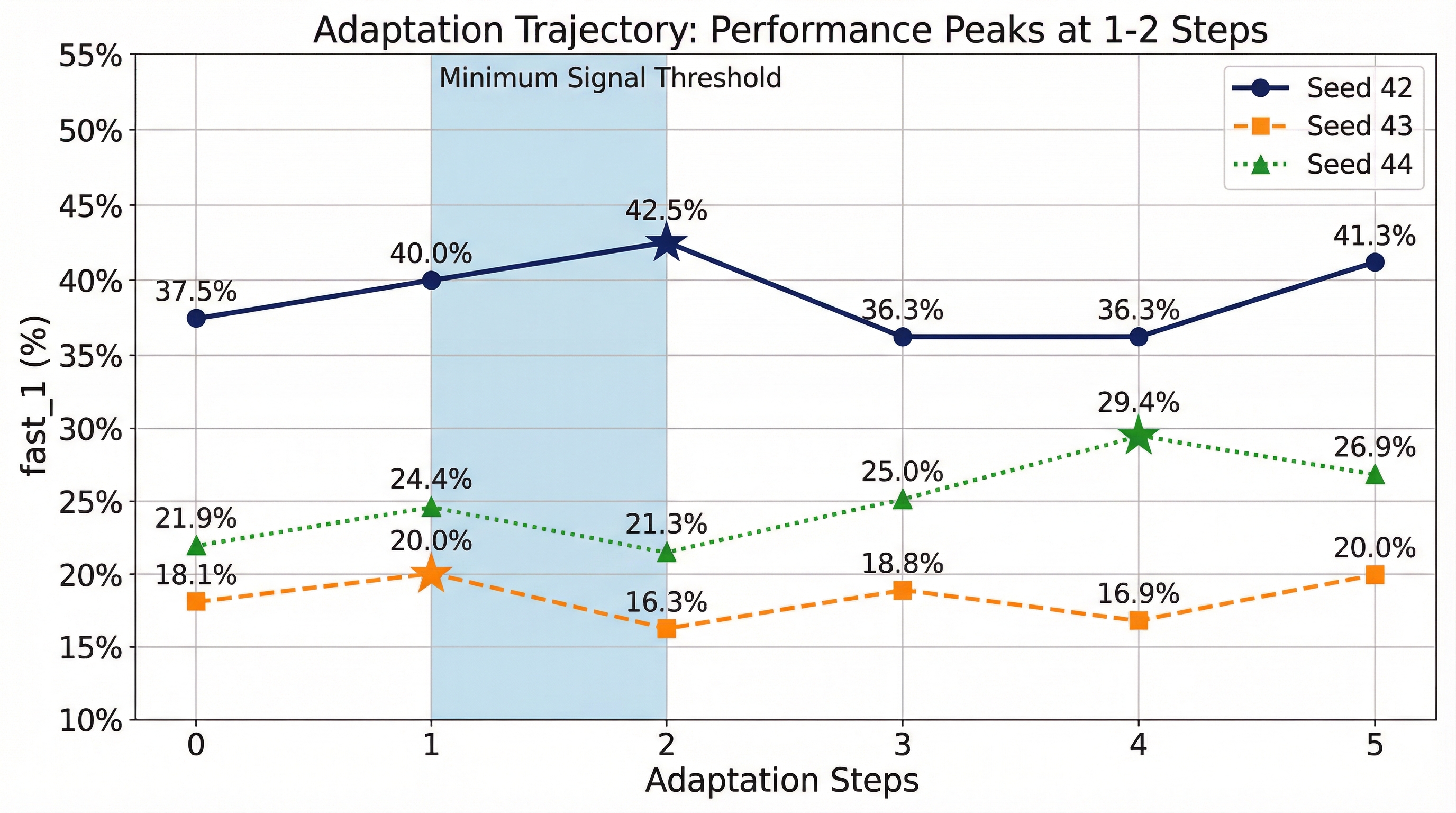
Performance peaks at 1-2 steps then regresses. Stars mark BoA-selected checkpoints. Over-sharpening persists across learning rates spanning three orders of magnitude.
When this works and when it doesn’t
Surprisal-guided selection requires two things: correct samples to select from, and enough logprob variance within each task.
Of 20 L1 eval tasks, 9 have high logprob variance (std > 1.0), tasks with diverse solution strategies that create a gradient for selection to exploit. The remaining 11 produce near-identical logprobs across samples, primarily convolution and normalization operations where the model converges to a narrow template. On those tasks, all selection strategies degenerate to random.
The adaptation regime also matters. When the base policy has >30% coverage on a task, gradient updates can refine solutions. Below that threshold, search preserves the diversity needed to find rare successes. Across both 5-task subsets, TTT underperforms Best-of-N by 9-21 percentage points.
Rich execution feedback provides no lift over prompt-only methods. Self-Distilled Policy Optimization (SDPO) in prompt-only mode achieves comparable results to TTT’s best checkpoint (30.4% vs 30.6%) under matched rollout budgets, consistent across 3 seeds. Adding execution feedback to SDPO hurts: feedback-SDPO drops to 26.3%, a 4.1 percentage point deficit. When the world provides continuous rewards, an AI teacher interpreting that signal becomes redundant.
One principle ties both failures together: gradient steps to saturation scale inversely with reward density. Dense continuous rewards (kernel speedup, 0x to 10x+) compress into weights in 1-2 steps. Sparse binary rewards (correct/incorrect) may require extended adaptation. TTT-Discover succeeds with ~50 steps on discovery tasks; the difference likely stems from reward density, as sparse-reward discovery may require extended exploration that dense-reward tasks do not. On KernelBench, the signal saturates immediately. The Best-of-N scaling curve in the teaser tells the same story from the search side: performance hits 99.9% at K=16. Sixteen samples suffice when rewards are dense. If you’re building a training pipeline and wondering whether TTT will help: check your reward density first.
What to do with this
These results apply to verifiable execution-grounded tasks: domains where a deterministic evaluator provides ground-truth feedback without human judgment. GPU kernel optimization, assembly superoptimization, formal theorem proving. The defining feature: the environment tells you exactly how good each output is.
For these tasks, surprisal-guided selection is zero-cost at inference. Sample K=16-64 candidates, filter for correctness, select by surprisal. No reward models, no reranking infrastructure.
I showed in a previous post that supervised fine-tuning plus test-time selection matched GRPO at Pass@4 on multi-turn tool-use. The pattern holds: when you have a verifier, smart selection often beats more training.
The over-sharpening dynamic parallels agent calibration failures. In my OpenSec work, frontier models correctly identify the ground-truth threat when they act but take incorrect containment actions in 45-97.5% of episodes. Over-sharpening and over-triggering are the same thing: the policy collapses its distribution and loses restraint. More adaptation makes models more confident about wrong actions, exactly what the NLL probe measures here. If your agents misbehave after fine-tuning, check whether you’ve trained past the sharpening threshold.
For evaluation design: benchmarks need to span both high-coverage and low-coverage tasks, because the optimal strategy flips at the boundary. Execution-grounded evaluators (deterministic feedback, continuous reward, scoring what the model does rather than what it claims) make this measurable. Static benchmarks that cover only one regime will mislead.
Can you skip evaluation with surprisal?
I tested whether ranking by surprisal before correctness evaluation could cut evaluation cost. Across 30 task-seed pairs, it does not work at small budgets. At m=5 (evaluating 8% of candidates), surprisal achieves 43% task success versus 59% for random. The extreme high-surprisal tail mixes expert solutions with malformed code the model correctly considers unlikely. Without the correctness filter, you cannot tell them apart.
The crossover is at m=16 (25% of K), where surprisal pulls ahead by 7.5 percentage points. Confidence is worst at every budget level. The correctness filter is not a convenience. It is the mechanism. Evaluate everything for correctness, then select by surprisal at zero cost.
What this doesn’t cover
Selection strategy analysis covers 10 task-seed pairs (5 tasks x 2 seeds). The primary comparison (80% vs 50%) shows a medium-to-large effect (Cohen’s h = 0.64). The sign test is underpowered by design at n = 10 (p = 0.125); the effect size and continuous speedup analysis are the primary evidence. Best-of-N covers all 20 L1 tasks. I tested a single 120B model. Transfer to other scales is open. Evaluation uses fast-proxy protocol (5 timing trials per kernel).
The inverse confidence-quality relationship may be domain-specific. In kernel optimization, rare creative solutions yield high speedups. In domains where the distribution mode represents optimal behavior, surprisal-guided selection could underperform. The surprisal signal also vanishes on 11/20 tasks where the model produces near-identical solutions.
Try it yourself
# Clone the repo
git clone --recursive https://github.com/jbarnes850/test-time-training.git
cd test-time-training
# Install dependencies
uv sync --extra dev
# Run Best-of-N with selection analysis
uv run python -m scripts.best_of_n \
--split splits/l1_seed42.json \
--subset eval \
--k 64 \
--max_tasks 20
Resources
Citation
@article{barnes2026surprisal,
title={Surprisal-Guided Selection: Compute-Optimal Test-Time Strategies for Execution-Grounded Code Generation},
author={Barnes, Jarrod},
journal={arXiv preprint arXiv:2602.07670},
year={2026},
url={http://arxiv.org/abs/2602.07670}
}
The question I started with: given a capable model, how should you spend test-time compute? Does test-time adaptation generalize to every setting? For dense-reward tasks with deterministic evaluation, it does not. TTT is worse than random. Gradient updates collapse the distribution and destroy the Expert Tail where optimal performance lives.
The answer: sample, filter, select by surprisal. The model’s least confident correct solutions are its best. That signal is already in the logprobs. Use it.