Hillclimb Anything - How to Make Benchmarks Adapt Online
TLDR A good frontier benchmark is not the hardest possible task set, but a living task distribution that keeps models failing in ways we can learn from. Once models saturate a benchmark, it becomes a regression test, which is still valuable but no longer tells you where the next capability boundary is. The evals that matter for frontier agent work stay partially unsolved. Not impossible, not trivial, but hillclimbable. An async online benchmark loop profiles the current solver, finds the live difficulty band, mutates tasks near that boundary, admits grounded tasks with learnable failure structure, and verifies the resulting frontier against stronger models.
Key terms used in this post
- Headroom is the part of an eval that a model has not saturated yet.
- Hillclimbable means the model partially succeeds, so the failure is still useful.
- Online loop means the task set updates from new model behavior instead of staying fixed.
- Grounded means the task can be checked against evidence outside the model’s text.
The loop is simple:
- Profile the current solver.
- Partition the task distribution into saturated, hillclimbable, and unreachable bands.
- Generate nearby mutations from parent tasks.
- Reject tasks that are ungrounded, trivial, or unreachable.
- Admit tasks that remain verifiable and hillclimbable.
- Periodically verify the frontier against stronger models.
- Feed those failures back into the next teacher cycle.
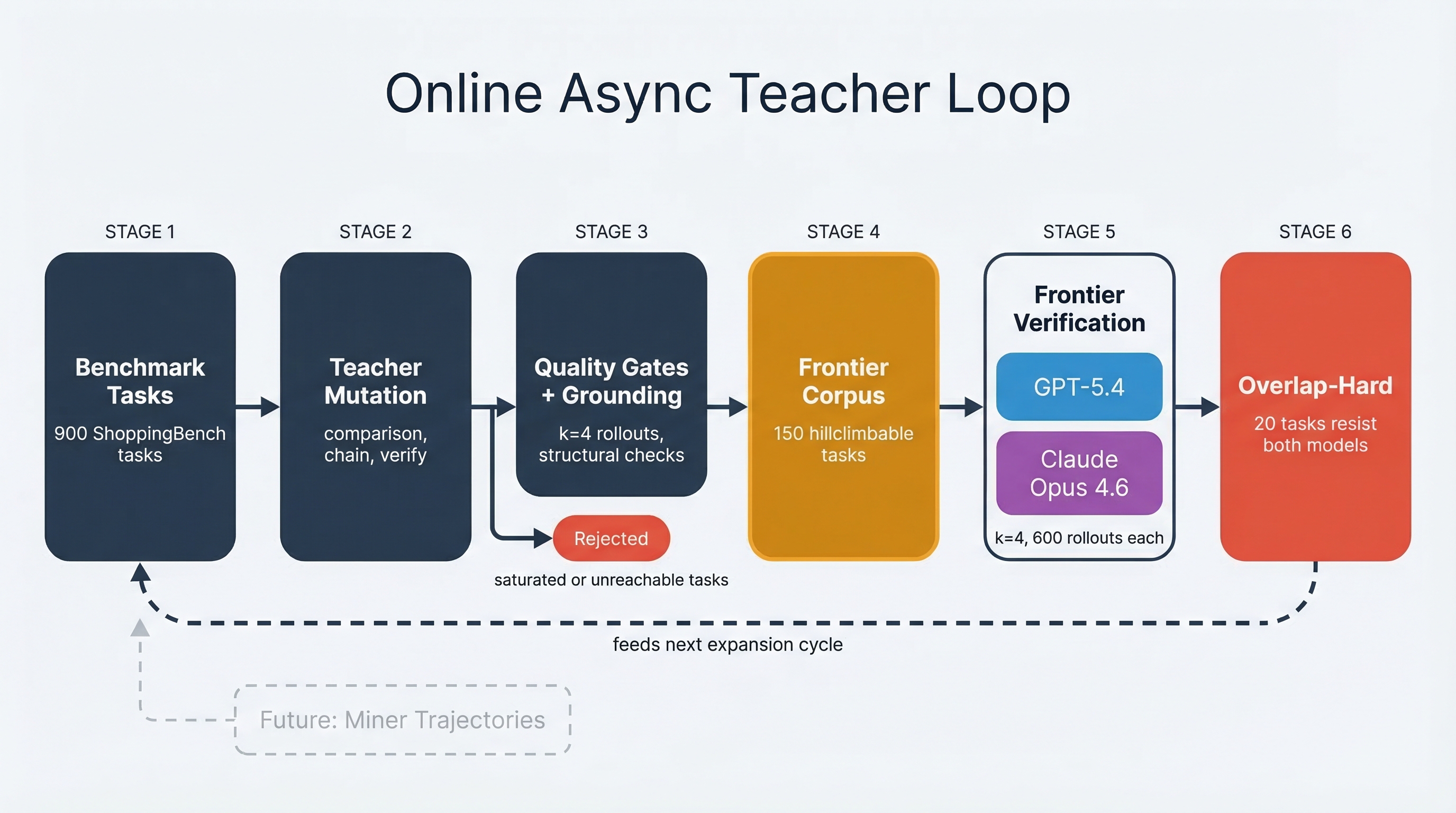
The async loop turns a fixed benchmark into a maintenance system. Admission is the step where candidate tasks are checked for grounding, replayability, and useful difficulty before they enter the frontier.
Benchmarks compress model behavior into a score we can compare across systems.Benchmark here means the tasks plus the scoring procedure. The task set defines what behavior is being measured. The score defines what counts as progress. That compression is useful while the task set has headroom. Once the top end saturates, the benchmark becomes regression coverage: still useful, but no longer a frontier detector.
Humanity’s Last Exam is the visible macro example. It was built with 2,500 expert-authored, closed-ended questions across more than 100 academic subjects, yet public frontier scores are already in the 40s.Humanity’s Last Exam was created by the Center for AI Safety and Scale AI as a broad, expert-level academic benchmark. As of April 24, 2026, the public Scale leaderboard top score is 46.4%. The same thing happens inside products. The useful eval is not the impossible one, but the one sitting just beyond the current system.
I call that band hillclimbable: the model has the component skills, but does not reliably compose them.Hillclimbable means the task is neither solved nor hopeless under the current solver. In the ShoppingBench runs below, I use mean reward above 0.02 and at or below 0.70. It finds the right product family but misses an attribute, searches correctly but fails to inspect, performs the arithmetic but forgets the voucher constraint, or resolves the web fact without binding it to the final recommendation.
These structured failures point to what to train, what to reward, what tool behavior to improve, and what future models still need to solve.
The inspiration comes from recent proposer-solver loops. Dr. Zero co-evolves search-agent training tasks without human training data, while Socratic-Zero uses a teacher, solver, and generator to build a closed loop for math-reasoning data.Dr. Zero introduces a data-free self-evolution loop for search agents. A proposer generates diverse, increasingly difficult but solvable questions for a solver. HRPO groups structurally similar questions to reduce sampling cost.Socratic-Zero uses three co-evolving agents. The teacher targets the solver’s weaknesses, the solver learns from preference feedback over trajectories, and the generator distills the teacher’s question-design strategy. The reported setup starts from 100 seed questions. Those loops evolve the training distribution. This one applies the same loop shape to the evaluation artifact itself.
ShoppingBench is the proxy in this post. It is an end-to-end shopping-agent benchmark where an agent searches a simulated shopping environment, inspects products, compares constraints, and returns a verifiable recommendation.ShoppingBench contains shopping tasks over a sandbox with more than 2.5 million real-world products. The task families include product search, shop-level constraints, voucher and budget reasoning, and web-grounded shopping queries. That makes it useful for studying benchmark maintenance, because shopping tasks fail in the same way many deployed agents fail. The model often has the pieces, but the composed behavior is brittle.
The broader question is how to maintain an agent benchmark after models start learning it. Recent saturation work frames the core failure as a loss of discriminative power among top models, and adaptive-testing work points in the same direction by selecting more informative items instead of treating every item as equally useful.Benchmark saturation is when top models can no longer be reliably distinguished by the benchmark. See When AI Benchmarks Plateau, which analyzes saturation across 60 text-based LLM benchmarks.Adaptive testing uses item difficulty and informativeness to choose what to test next. See Adaptive Testing for LLM Evaluation (ATLAS), which applies item-response methods to LLM benchmarks. ShoppingBench is the worked example.
Finding the Live Band
Before changing a benchmark, the first question is where it still gives signal. The baseline profile used GPT-OSS-120B on the original 900 ShoppingBench tasks, because it is competent enough to use tools but not strong enough to flatten the distribution.
The baseline ran at k=2 and reached about 45% CAR pass@1 and 32% binary ASR pass@1.CAR is cumulative average relevance, a continuous product-relevance score with partial credit. ASR is binary absolute success rate. Binary success says whether the model fully solved the task. CAR shows that it often found something relevant but missed an exact constraint. That gap is where hillclimbable signal lives.
The baseline split was a distribution, not a single score. Out of 900 tasks, 336 were saturated, 181 were hillclimbable, and 383 were unreachable. Product Finder was mostly solved at 80.6% CAR, making it more useful as regression coverage than frontier training. Voucher and budget tasks carried the richest hillclimbable signal, while multi-product and web-grounded tasks exposed deeper failures in tool use, constraint composition, and external grounding.
The baseline expansion used offline teacher-guided mutation. Starting from mastered parents, the teacher generated nearby variants, then the system filtered for novelty, decision-boundary shift, and grounded solvability.Teacher-guided mutation means using a stronger model or prompt program to create a nearby variant of an existing task. The parent task supplies the grounded shopping context. The mutation changes the reasoning pressure. That pass produced 23 admitted hillclimbable tasks from 346 teacher attempts after 100 quality-filtered mutations. Nearby mutations could move tasks back toward the frontier, but the workflow was still batch-shaped: generate, test, inspect.
For a live benchmark, the loop has to see failures as they arrive and keep moving the task distribution while the solver changes.
Remapping the Bands
The online loop starts by refreshing the map. In the expansion phase, I reprofiled the same 900 tasks with Qwen 3.5 35B at k=4, producing four sampled attempts per task and 3,600 total rollouts. This was not a ranking run against GPT-OSS. It was a denser view of where partial success lived.
The mean reward was 0.437 and the median reward was 0.388, which put Qwen in the useful part of the distribution. The failures were not dominated by harness confusion, and the benchmark was not saturated.
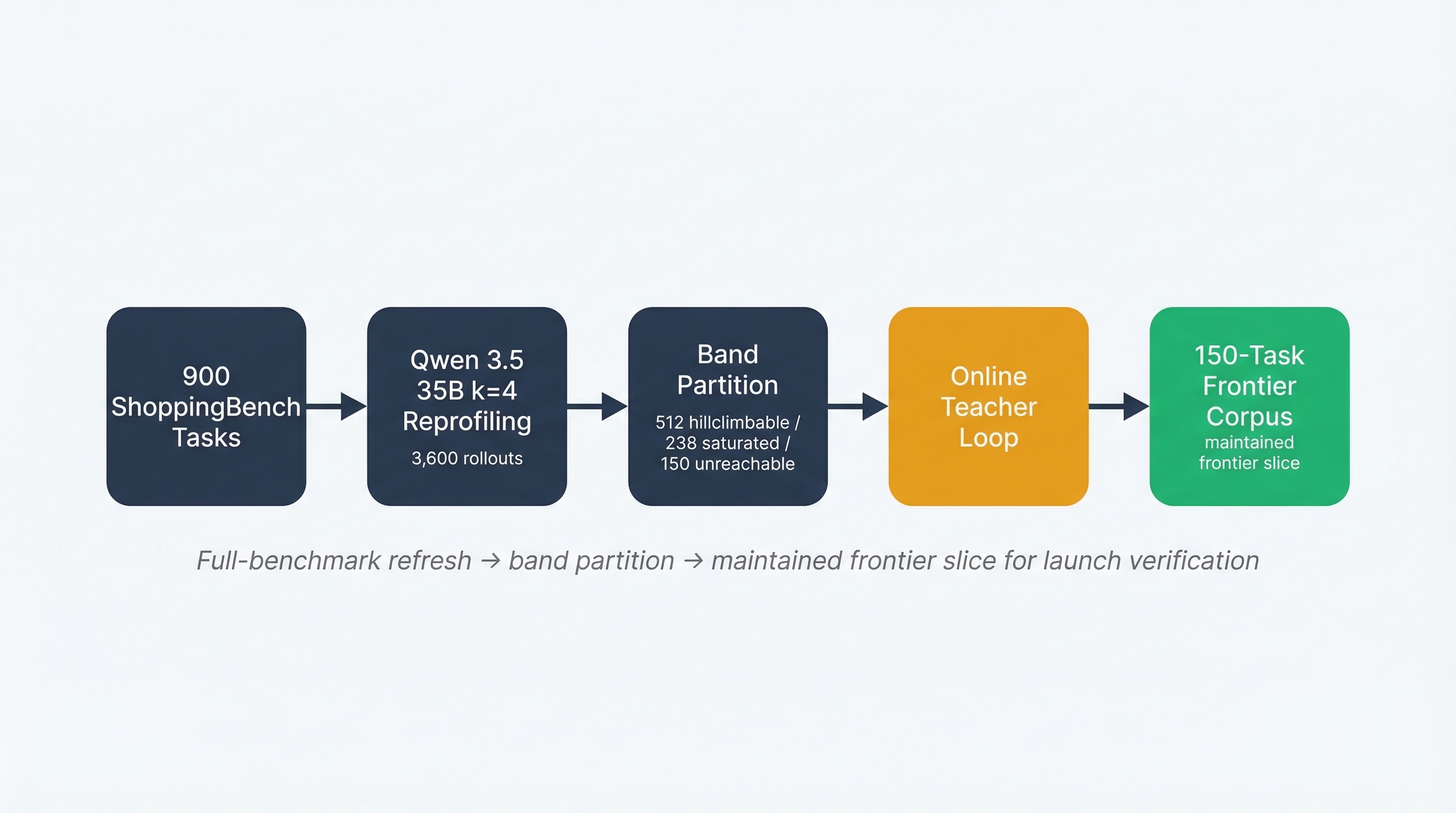
The profiling pass is not a leaderboard run. It is a map of where the current solver still produces partial, useful failures.
The map changed sharply. The hillclimbable band expanded to 512 of 900 tasks, while 238 were saturated, 150 were unreachable, and 452 stayed below 0.40 reward. The exact repartition matters less than the new supply of parent tasks near the decision boundary.
The traces were consistent with a specific failure shape: Qwen usually had the basic tool skills, but broke down when it had to bind multiple constraints into one final recommendation. Voucher tasks exposed arithmetic and threshold mistakes, web tasks exposed external-grounding failures, and shop tasks exposed same-seller and multi-item composition problems. Useful mutations pushed on places where the model was already close, testing whether the solver could compose skills it mostly already had.
Turning Traces into Tasks
The common mistake is to treat raw agent traces as training data. They are logs. A trace tells you what the agent did, which tools it called, where it hesitated, and what answer it produced, but it does not give you a replayable task, a stable intent, or a grounded outcome.
That conversion is the work. For benchmark maintenance, a failure trace becomes useful when it can be turned back into a replayable task with captured intent and a grounded outcome. A new policy has to attempt the same task under comparable conditions, and reward has to come from evidence rather than a guess from the transcript.
ShoppingBench is useful here because those pieces are explicit. The user intent is part of the task, the environment can be replayed, and the outcome can be checked against product data, shop metadata, voucher rules, web facts, and verifier logic.Grounded outcome means the score is tied to evidence outside the model’s text. In ShoppingBench, that evidence comes from the product catalog, shop constraints, voucher rules, web facts, and task verifier. That makes the trace convertible. A failure becomes evidence for where the next task can put pressure.
The async teacher loop does that conversion. It starts from a parent task near the boundary, uses the failure trace to propose a nearby mutation, then routes the candidate through rollout and verification before it can enter the frontier.Admission means the task is accepted into the maintained frontier set. A candidate has to be grounded, verifiable, nontrivial, and hillclimbable under the current solver. The teacher preserves the original intent while moving the decision boundary.
Async matters because admission is bursty. A parent-mutation round can starve or flood the frontier before the next profiling pass catches the drift, so profiling, mutation, rollout scoring, admission, and verification need to move as separate jobs.
In this run, the loop generated 894 candidates, admitted 177 hillclimbable tasks, and retained a 150-task frontier slice. The numbers are less important than the shape of the system. Model behavior becomes grounded candidate tasks, trivial and impossible tasks are rejected, and the retained set keeps producing useful failures.
Verifying the Frontier
A frontier produced by a teacher loop is still only a hypothesis. It says the tasks look useful for the current solver, but not whether they remain useful for stronger systems. Verification checks whether the maintained slice still has headroom when the solver changes.
I verified the 150-task slice against GPT-5.4 and Claude Opus 4.6. Both models ran k=4 on the same tasks, with the same verifier and tool registry. That produced 1,200 verifier rollouts.
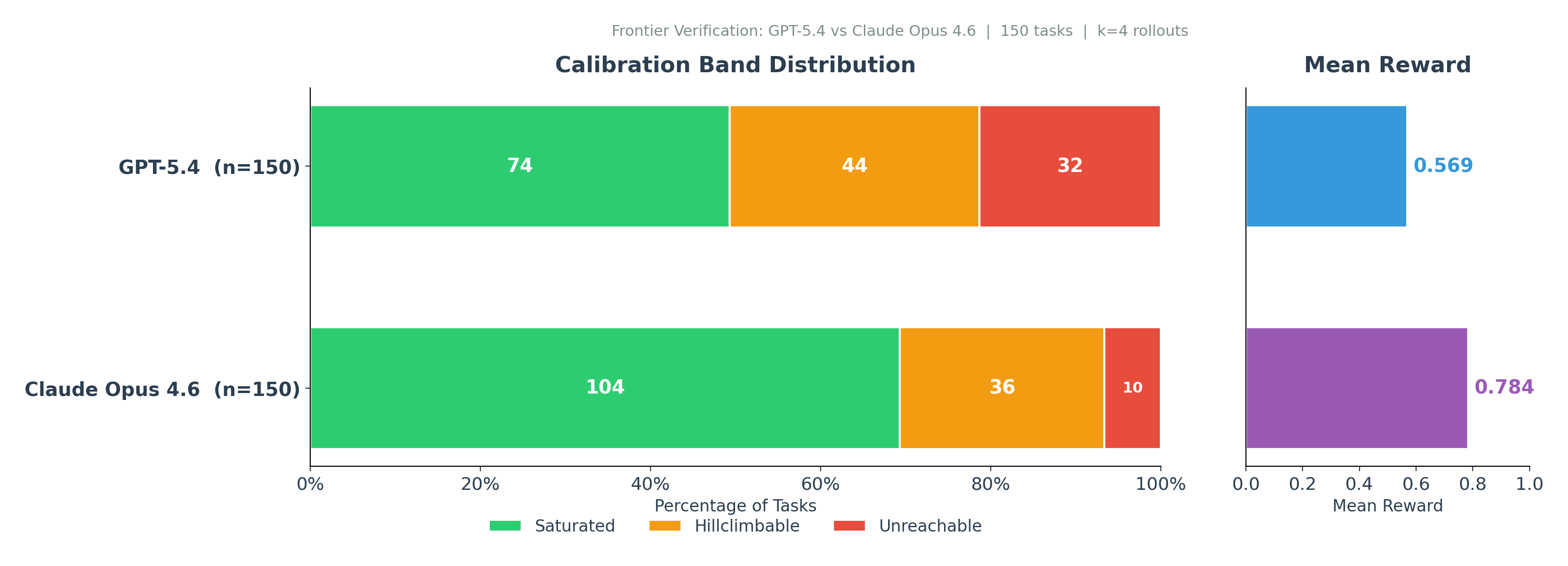
Frontier verification asks whether stronger models still leave enough unsolved structure for the slice to matter.
GPT-5.4 saturated 74 of the 150 tasks, but left 44 hillclimbable and 32 unreachable. Claude Opus 4.6 was stronger overall, saturating 104 tasks, but still left 36 hillclimbable and 10 unreachable. The point is that both models still left structured work on the table, which the overlap-hard analysis makes inspectable.
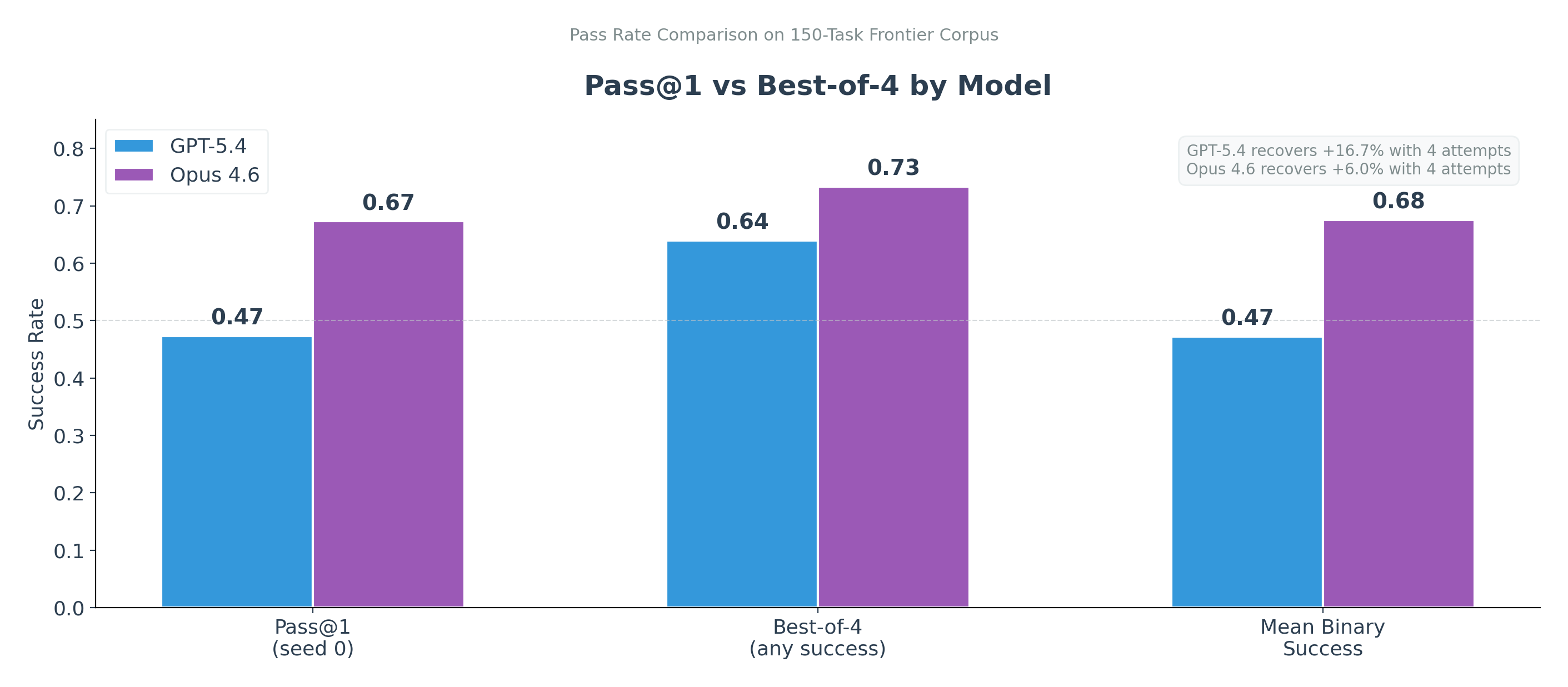
The gap between one attempt and four attempts is a useful signal. It means the task is sometimes within reach but not reliably executed.
The pass-rate comparison shows the same thing from another angle. GPT-5.4 moved from 0.47 pass@1 to 0.64 best-of-4, while Opus moved from 0.67 to 0.73. That gap matters because some tasks are solvable by the model, but not reliably. The capability is in the model’s support, but the policy does not consistently execute the right chain.
That is what headroom looks like. The task is sometimes solved, which means the failure contains information.
The verifier traces also showed model-specific failure shapes. GPT-5.4 often failed before completing the chain, while Opus more often completed the tool sequence and still missed the final verification or comparison constraint. Fine-grained attribute verification, material or ingredient checks, comparison across verified candidates, voucher arithmetic, and multi-item decomposition remained hard across both models.
The Overlap-Hard Canary
The most useful output of frontier verification is the overlap-hard set, not the mean score.
GPT-5.4 left 55 tasks below 40% mean reward and Opus left 24. Twenty stayed below 40% on both models, with four scoring 0 on both.
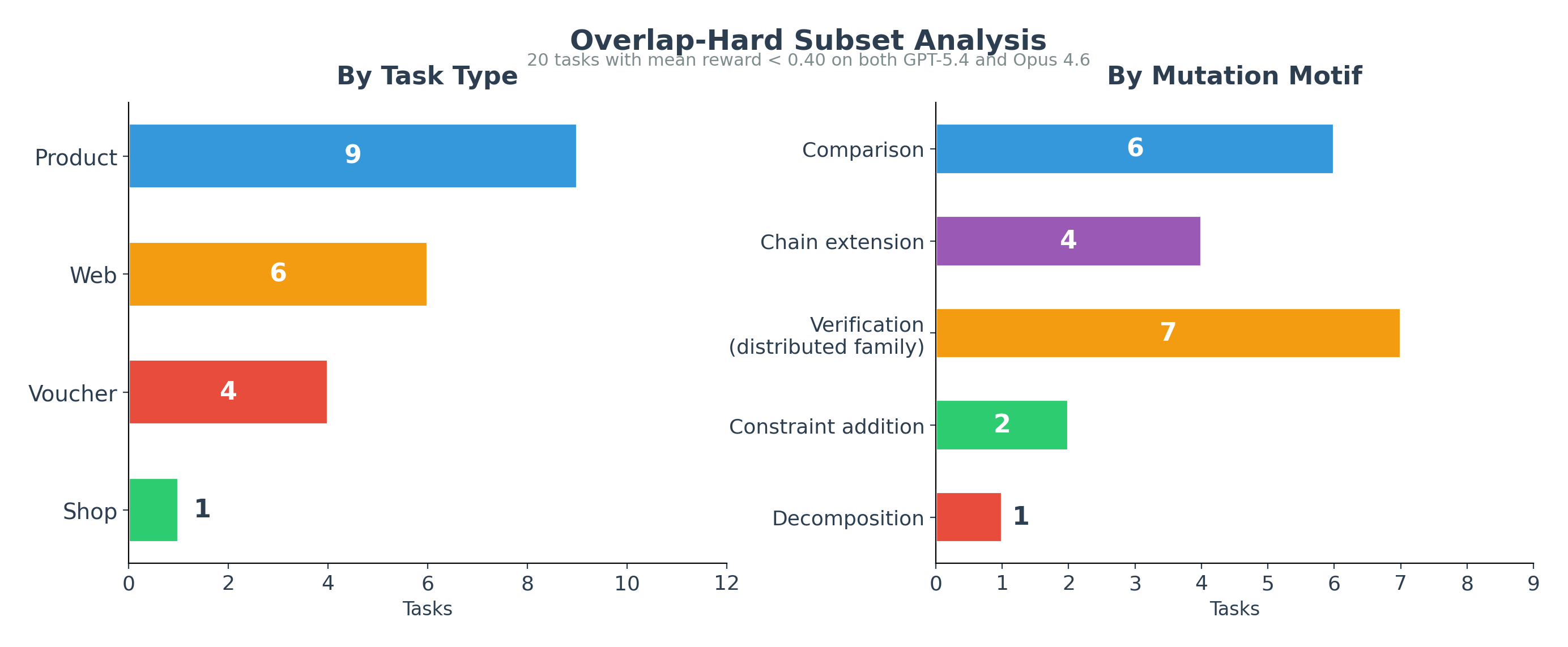
The overlap-hard set is the canary set. It is small enough to inspect and hard enough to reveal whether the frontier has moved.
The exact task strings are not the real frontier. They are instances of a more durable reasoning pattern:
- latent attribute verification
- comparison across verified candidates
- cross-domain composition
- voucher arithmetic under same-shop constraints
- multi-item decomposition
The mistake would be to preserve the literal prompts. Better to preserve the pressure: verify the attribute that changes the recommendation, compare across verified candidates, compose external facts with product constraints, and decompose multi-item requests before recommending. The frontier lives in those pressures, not in the exact words of a shopping prompt.
Saturation as Event
In a static benchmark, saturation is the end of the story. The leaderboard compresses, scores stop separating models, and the benchmark becomes historical context. In an online benchmark, saturation is an event. It tells the teacher to generate a new frontier.
For RL curricula, the hillclimbable band is the training signal, not the full benchmark. Tasks below 0.02 reward contribute no gradient, and tasks above 0.70 contribute no new direction. Concentrating rollouts on the live band is cheaper than uniform sampling and aligns each update with capability the model is already close to. The same logic sharpens evaluation design: a benchmark that stays partially unsolved keeps measurement useful across model generations, because the score tracks a moving frontier instead of compressing to a ceiling.
In this design, the profiler and verifier roles stay separate. A cheaper, protocol-reliable model maps the frontier and runs the teacher loop, while stronger frontier models audit the result and feed their failures into the next cycle. ShoppingBench is one instance of that pattern. The same loop applies anywhere the benchmark has an executable verifier and a task structure that can mutate without losing grounding.
Limitations
The loop maintained a useful frontier slice, but it did not solve benchmark maintenance in general.
Admission rate is still an optimization target. The online loop admitted 177 hillclimbable tasks from 894 generated candidates, enough to build the slice but not yet efficient.
Cost is part of the design. This pass used 3,600 Qwen profiling rollouts, 894 generated candidates, and 1,200 frontier-model verification rollouts. That is workable for an eval-maintenance run, but too expensive to treat as a casual smoke test.
The thresholds are operational. I used hillclimbable = (0.02, 0.70], unreachable = <= 0.02, and saturated = > 0.70 on mean reward.These are mean-reward bands. They are useful for this maintenance loop, not universal psychometric laws. Different domains may need different thresholds. The cut points matter less than the discipline of separating trivial, learnable, and currently unreachable tasks.
The source files use pass_at_k for mean binary success over four rollouts, not strict any-of-4 pass@k. When I refer to best-of-4, I mean the any-success view shown in the verification figure.
The overlap-hard tasks are not sacred. Their literal text is instance-specific. The durable target is the failure pattern, not the prompt string.
Longitudinal comparability is still hard. If the benchmark keeps changing, progress over time depends on anchor tasks, versioned slices, or an item-response-style linking strategy. This post focuses on frontier maintenance, not score linking.
References
- Akhtar, M., Reuel, A., Soni, P., et al. “When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation.” arXiv preprint arXiv:2602.16763, 2026.
- Epoch AI. “Humanity’s Last Exam benchmark overview.” epoch.ai/benchmarks/hle.
- Li, P., Tang, X., Chen, S., Cheng, Y., Metoyer, R., Hua, T., and Chawla, N. V. “Adaptive Testing for LLM Evaluation: A Psychometric Alternative to Static Benchmarks.” arXiv preprint arXiv:2511.04689, 2025.
- Phan, L., Gatti, A., Han, Z., Li, N., et al. “Humanity’s Last Exam.” arXiv preprint arXiv:2501.14249, 2025. Public leaderboard: labs.scale.com/leaderboard/humanitys_last_exam.
- Wang, S., Jiao, Z., Zhang, Z., Peng, Y., Xu, Z., Yang, B., Wang, W., Wei, H., and Zhang, L. “Socratic-Zero: Bootstrapping Reasoning via Data-Free Agent Co-evolution.” arXiv preprint arXiv:2509.24726, 2025.
- yjwjy. “ShoppingBench: A Real-World Intent-Grounded Shopping Benchmark for LLM-based Agents.” GitHub repository, github.com/yjwjy/ShoppingBench, 2025.
- Yue, Z., Upasani, K., Yang, X., Ge, S., Nie, S., Mao, Y., Liu, Z., and Wang, D. “Dr. Zero: Self-Evolving Search Agents without Training Data.” arXiv preprint arXiv:2601.07055, 2026.