Agents notice the right evidence, then commit to the wrong edit.
Across six frontier models the failure repeats. The agent reads the public evidence, states the rule for rejecting an attractive but wrong signal, then commits to that signal when it has to choose. The strict solve rate is 11.3%, and no model clears 15%.
By workflow family
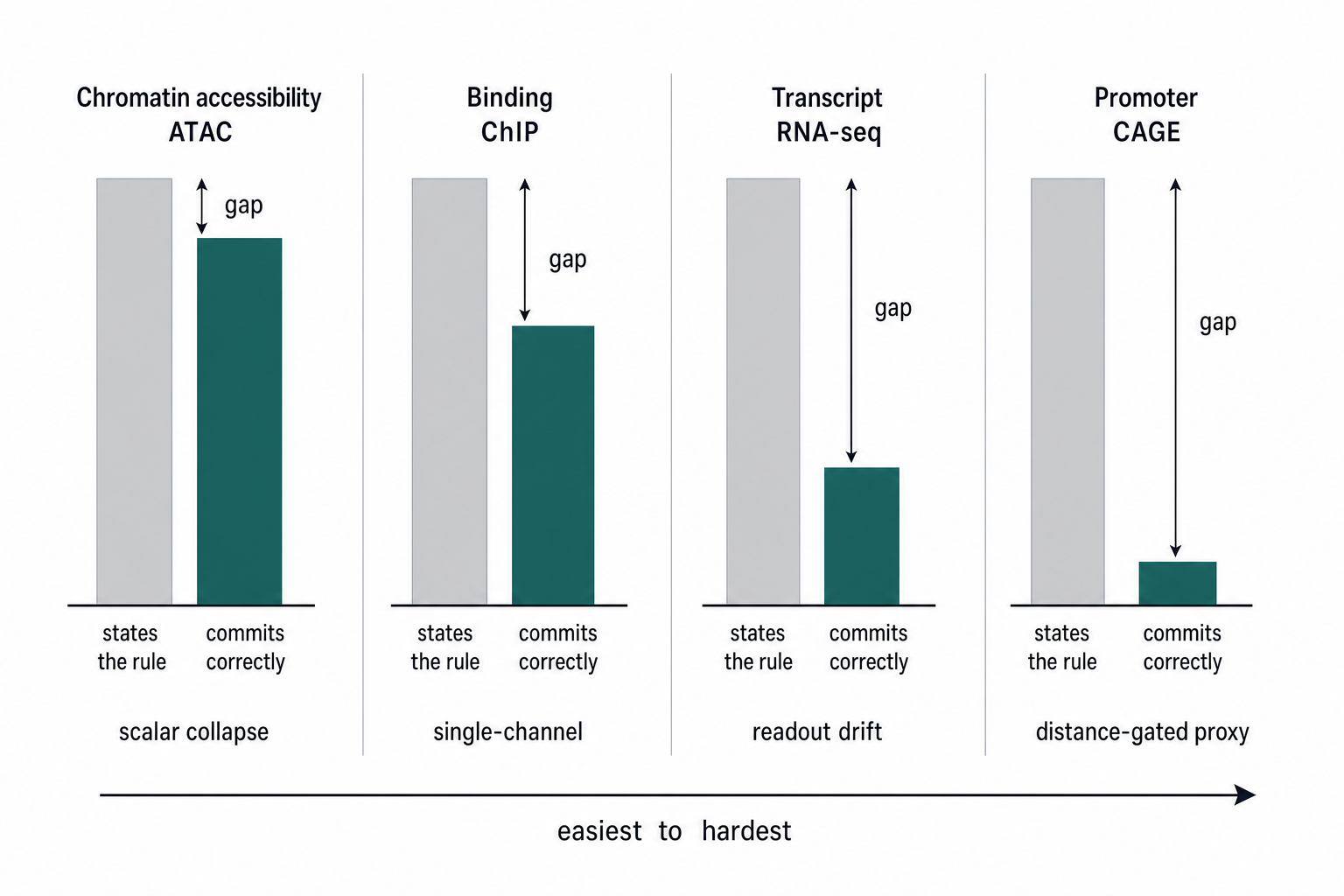
One task, four regulatory readouts.
Each family is balanced across 11 loci, 15 tasks each, so a family result is not a single-locus artifact. Counts are six-provider runs.
Workflow family
Tasks
Solve · near · fail
Solve rate
Failure shape
Solve Near-miss Failure
The point
Models follow the loudest public signal, even when it points away from the readout.
Promoter-output triage, the CAGE family, is the hardest at 5.6%, yet it produces 77 near-misses across 180 runs. Agents correctly favor the edit near the promoter and still miss the transcription start site CAGE scores. The family agents solve least is the one where the most salient public signal sits farthest from the requested readout.
This mirrors the scBench result in single-cell analysis, where agents run every plausible step and miss the one that decides the outcome. The question the trace answers is not only whether the final edit is correct, but whether the agent weighed the evidence specific to this readout against the proxy that looks strong everywhere.
For each assay family, agents state the proxy-rejection rule far more often than they commit to the hidden-verified choice. The gap widens as the requested readout decouples from the most salient public signal, from chromatin accessibility to promoter output. The committed bar marks a hidden-verified solve, not a wet-lab outcome.
Near-miss composition
Even the close calls are the model chasing the obvious public signal.
All runs pass the public and grading interface, so non-solves are scientific search failures rather than packaging breakdowns. Of the 252 valid near-misses, 240 carry a quality label.
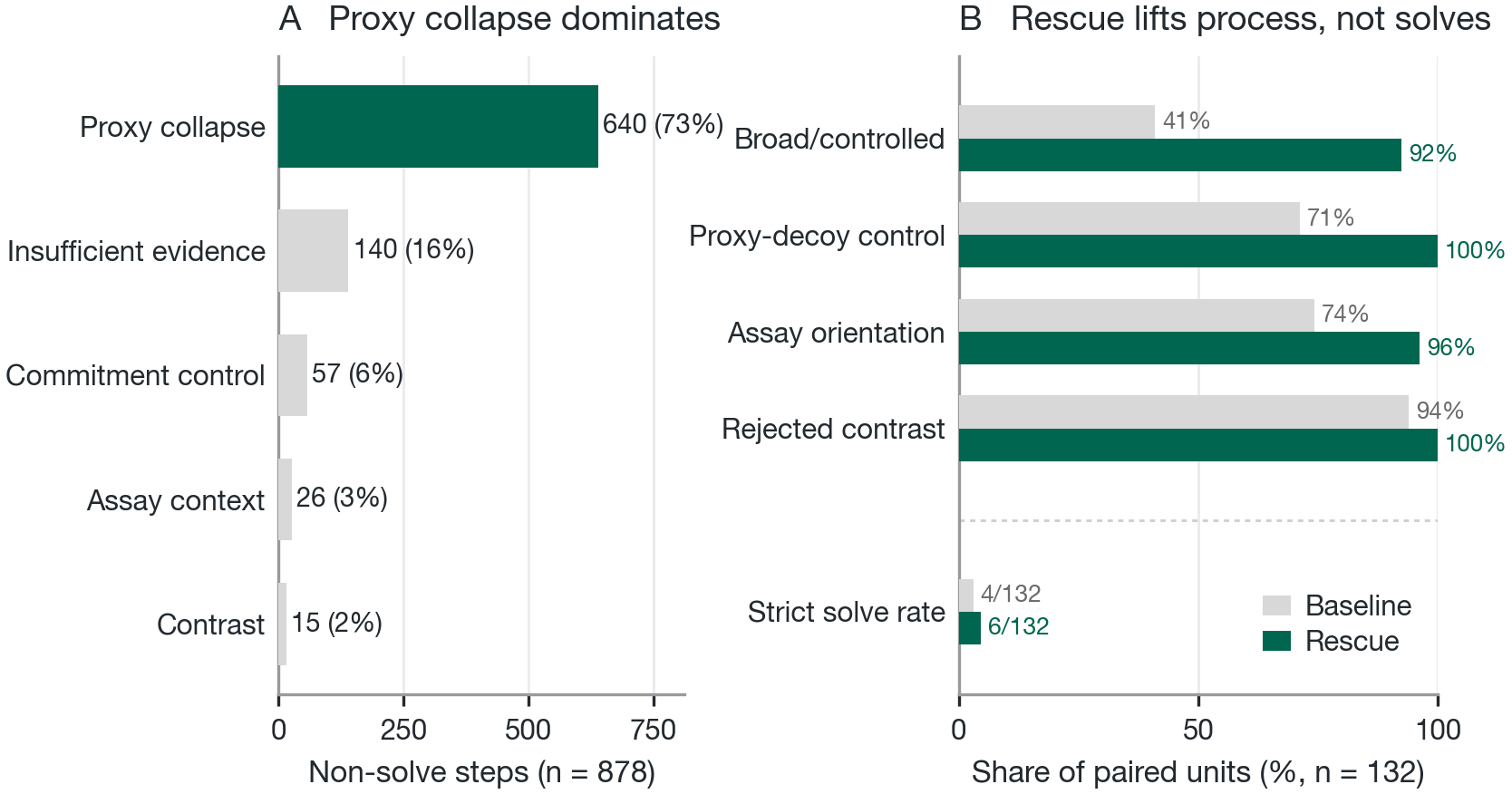
Of the 240 labeled near-misses, 32 are scientifically mature, weighing alternatives and treating the hidden objective as uncertain. 153 do real biological search but get pulled to the obvious public signal at the final choice. 55 lean on a public ranking from the start with little search. Public scalar collapse drives 189 of the 252 near-misses, and the same pull accounts for 640 of the 878 non-solves overall.
Expert-method rescue
A workflow checklist lifts process more than solves.
A paired diagnostic tests whether better process can fix proxy-collapse. It appends a hidden-blind workflow checklist to the same tasks and replays them. The checklist describes how to orient to the assay, build an evidence table, name public decoys, and contrast alternatives, and carries no hidden answer, rank, score, or candidate hint.
Over 132 paired model-task units, the checklist lifts observable workflow behavior far more than hidden-verifier solves. Proxy-decoy control rises from 71 to 100 percent and broad controlled exploration from 41 to 92 percent, while strict solves move only from 4 to 6. Rescue is a paired diagnostic. It does not change the leaderboard.
The checklist lifts process across the board while strict solves barely move, from 4 to 6 of 132. If the bottleneck were workflow organization, fixing the workflow would recover solves, and it does not. The residual difficulty is the scientific decision itself, where the public evidence still points agents toward edits that fail the hidden, model-backed objective. The benchmark is testing judgment about the biology, not formatting.