Verifier-Anchored Task Discovery
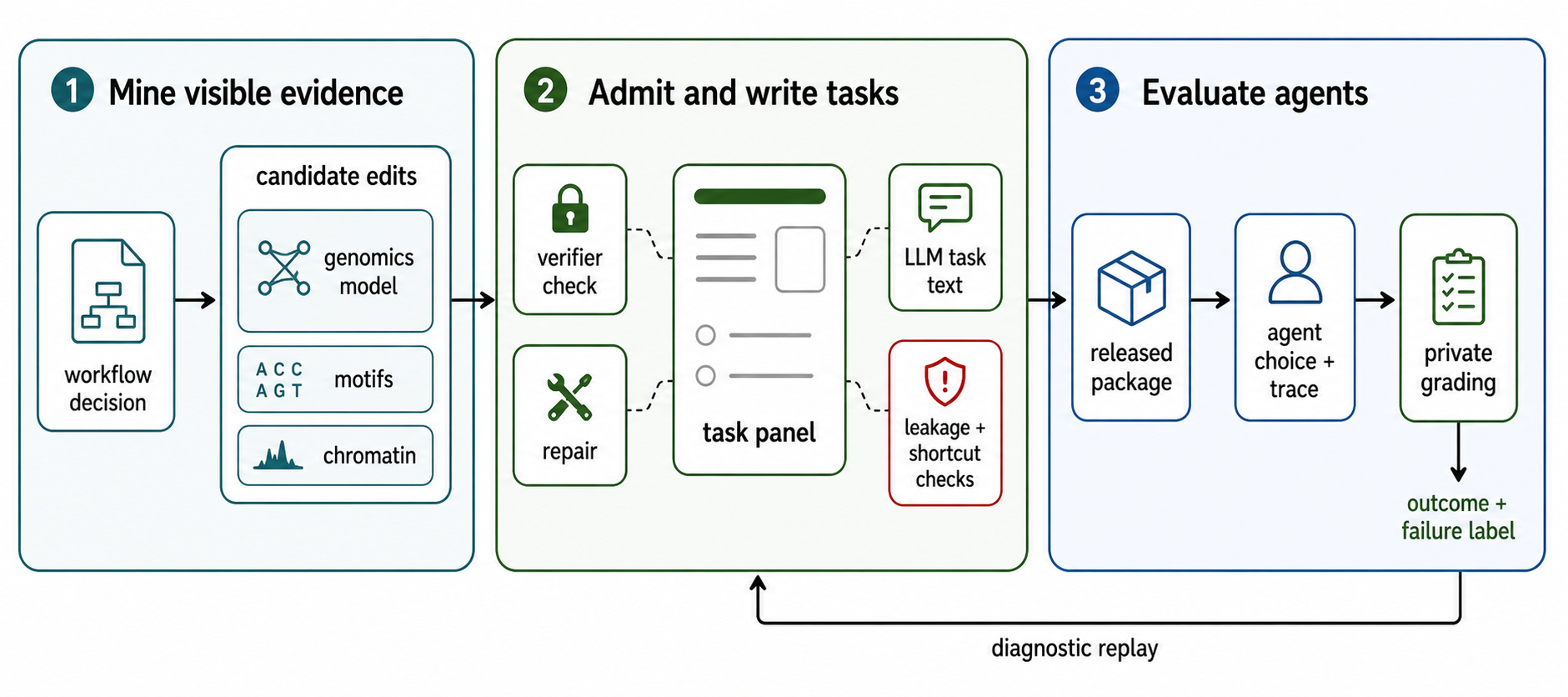
Latent Mining is a data-generation and benchmark-construction method organized around one question. Where do model-internal or model-disagreement signals reveal an unresolved scientific transition that can be packaged as a task? It starts from a workflow decision a scientist would face, reads the release-safe evidence that decision would draw on, and mines it for the cases where public signals point somewhere but do not settle the answer.
Only after mining does a hidden verifier enter and grade each candidate privately. A task is admitted when the hidden answer is well separated from the attractive public alternatives, and when no single public score, leaked field, or metadata artifact can recover it. Leakage scans and shortcut probes reject or repair any task that an agent could solve by cheating rather than by judgment. Plausibility alone never admits a task.
For this release, we applied Latent Mining to scientific workflows within computational biology, starting with regulatory-intervention triage. The agent compares candidate noncoding edits for one assay and cell context, weighing sequence-model scores, motif and chromatin annotations, locus context, and disagreement across public signals. Each signal carries information about the hidden regulatory effect and none recovers it, which makes the decision a calibration problem rather than a lookup.
Every admitted task answers one design question. Can we name the lab workflow decision, the public evidence, the hidden verifier, the failure label, and the replayable trajectory? A panel enters the benchmark only when all five are present, which keeps task construction from collapsing into generic question answering.
Define the workflow decision
We begin with the action the agent is supposed to take.
In this biology release, the decision is constrained. The agent must choose the candidate regulatory edit most likely to improve a hidden regulatory outcome for a specified assay and cell context. This is a focused test of regulatory-genomics triage.
decision · constrained actionGenerate candidate interventions
We use domain models and retrieval to produce plausible candidate edits, drawing each from a different view of the intervention space. The output is the comparison set for one task, several edits that all look defensible on some public signal. No source is trusted as the answer. They exist to populate a slate of credible alternatives.
generate · candidate spaceExpose imperfect public evidence
Each task shows public evidence from sequence-model likelihood summaries, embedding-distance features, motif and PWM changes, edit geometry, locus metadata, assay family, chromatin context, and disagreement across public signals.
This is where difficulty is set. A task is only kept if no single public score, motif heuristic, source model, or generic mechanism story is enough to solve it, so the agent has to weigh signals against each other.
expose · imperfect evidenceHold out verifier-backed outcomes
Candidate edits are scored by a private, model-backed objective the agent never sees. In this release it is a hidden regulatory-effect estimate for the requested assay and cell context, fixed during construction before any agent runs.
We treat this as a verifier for building and grading tasks, not as experimental truth. A selected edit still needs lab validation, and a grading disagreement can reflect the verifier rather than the agent.
hold out · private objectiveBuild contrastive panels
Each task is a panel of candidate edits the agent compares directly. The distractors are deliberate, an outcome-proximal near-miss, an edit that a single public scalar makes look strongest, and same-context variants.
The panel is built so the attractive public proxy and the hidden answer point to different edits, which is the exact commitment where agents fail.
build · contrastive panelsAudit and calibrate
Every task is checked for leakage, shortcut features, public-interface validity, grading-interface validity, and calibration behavior across frontier agents.
The failure mode we want to study is not prompt confusion. It is the gap between noticing public regulatory evidence and using it to make the right intervention decision.
audit · calibration + tracesThe latent object is the boundary between public biological priors and withheld verifier-backed outcomes. We mine that boundary because it reveals where current scientific models produce signals that are useful enough to reason with, but incomplete enough that agents still need calibrated domain judgment.
Public evidence the agent sees