Do Language Models Know When to Change Their Mind?
Working technical report. Code at github.com/jbarnes850/metacognition.
What this is. A mechanistic experiment on small, local models (Qwen3.5 0.8B–9B) to understand how models decide whether to change their answer when someone pushes back. I use signal detection theory — a framework from psychology — to measure whether models can tell good feedback from bad. The experiments are intentionally small-scale: the goal is to validate a measurement method, identify the underlying mechanisms, and spur broader research at frontier scale.
Terms used in this post:
- d-prime (d’): A single number measuring how well the model distinguishes valid from invalid critique. Higher = better discrimination. Zero = can’t tell the difference at all.
- Hit rate: How often the model correctly revises when the critique is actually right.
- False alarm rate: How often the model incorrectly revises when the critique is wrong. This is the sycophancy signal.
- Criterion c: The model’s overall bias toward revising or resisting, independent of discrimination. Negative = tends to revise everything. Zero = no bias.
- Linear probes: Simple classifiers trained on a model’s internal activations to test what information it has encoded at each layer — a way to read the model’s mind.
- Cosine similarity: Whether two internal signals point in the same direction. -1 = opposite, 0 = independent, +1 = aligned.
Autoresearch has taken the field by storm. Point a model at a training setup, let it modify code, run experiments, check results, and iterate. 45,000 stars in two weeks. The promise is real: put your hardest questions on autopilot and wake up to a better model.
This loop has an assumption worth examining. When the agent sees a result that contradicts its current approach, does it actually update? Or does it overfit to what worked before, discarding conflicting signal? The loop only works if the model knows when to change its mind.
I ran experiments to find out. Competence and control turn out to be separable. Models learn to represent correctness internally before they learn to use that representation to resist invalid challenges. The connection between knowing and acting develops with scale — but only on tasks where the model has structured domain knowledge. On commonsense reasoning, metacognitive control plateaus early. The type of knowledge matters as much as the amount.
A model that scores 90% on a benchmark but flips its answer 75% of the time when someone confidently tells it the wrong thing is not a 90%-capable system. Its capability depends entirely on whether anyone pushes back. The number that matters for deployment — and for autonomous research loops — is not “how often is it right” but “how often does it hold when it’s right and fold when it’s wrong.”
Google DeepMind’s cognitive framework for measuring progress toward AGI breaks general intelligence into ten cognitive faculties and identifies where the benchmark gaps are largest. Metacognition is one of those gaps.
Metacognition is the ability to monitor and control your own thinking. In their taxonomy, it splits into three layers: knowing your limitations (metacognitive knowledge), catching your errors (metacognitive monitoring), and acting on what you catch (metacognitive control). Most existing work targets the first two. Calibration benchmarks ask: does the model know what it knows? Abstention benchmarks like AbstentionBench (Kirichenko et al., 2025) ask: does the model know when it should refuse? Wang et al. (AAAI 2025) proposed separating metacognition from cognition using signal detection theory, but focused on monitoring (failure prediction), not control.
I focus on the third layer. Metacognitive control is the decision to revise or resist when presented with new evidence. The question is simple: does the model know when to change its mind?
Existing benchmarks can’t tell the difference
Sycophancy is a known failure mode. OpenAI documented it in GPT-4o, where the model excessively validated user beliefs instead of providing accurate information. Anthropic observed it in Claude, where models would say “You’re absolutely right” and reverse correct answers under minimal pressure. Both labs treated it as an alignment bug to be patched. I think the framing is incomplete: sycophancy is a symptom of missing metacognitive control, not a standalone defect.
The research literature has grown around this. The Certainty Robustness Benchmark (Saadat and Nemzer, 2026) tests whether models maintain correct answers when told “You are wrong!” Claude Sonnet 4.5 shows an 82-point accuracy collapse under explicit contradiction. SYCON-Bench (Hong et al., 2025) measures multi-turn sycophancy across debate, ethics, and false presupposition scenarios. TRUTH DECAY (Liu et al., 2025) generates convincing-but-false rationales and measures accuracy degradation over turns.
These benchmarks share the same limitation: the critique never varies in quality. In the Certainty Robustness Benchmark, the challenge is “You are wrong!” with no reasoning. In SYCON-Bench, the user is always wrong. In TRUTH DECAY, the generated rationales are always false. There is no condition where the model should revise.
This means existing benchmarks measure social compliance, not evidence evaluation. A model that always resists would score perfectly. A model that carefully weighs critique quality and revises only when the evidence is genuinely corrective would score the same as one that stubbornly ignores everything. The benchmarks cannot tell these two behaviors apart.
The construct I care about is discrimination: can the model tell good evidence from bad when deciding whether to change its answer?
Kumaran, Fleming et al. (DeepMind, 2025) documented the pathology — overconfidence plus oversensitivity to contradiction — but did not vary critique quality. My work extends theirs.
How I measured it
I adapt Fleming and Lau’s (2014) signal detection framework for metacognitive sensitivity to belief revision. The “signal” is a critique with genuinely corrective reasoning. The “noise” is a critique with plausible-but-wrong reasoning. The “response” is whether the model revises:
- Hit: Model was wrong, receives valid critique, revises. Correct behavior.
- Miss: Model was wrong, receives valid critique, holds firm. Failure to update.
- False alarm: Model was right, receives invalid critique, revises. Sycophancy.
- Correct rejection: Model was right, receives invalid critique, holds firm. Correct behavior.
d-prime = Z(hit rate) - Z(false alarm rate). It measures how well the model can tell valid from invalid critique, independent of its overall tendency to revise or resist. A model that always revises has d-prime near zero. A model that never revises also has d-prime near zero. Only a model that selectively revises based on critique quality produces high d-prime.
For stimuli, I use the DS Critique Bank (Gu et al., 2024): 6,678 instances of student model answers paired with critiques of varying quality. The valid critiques pinpoint specific errors with corrective explanations. The invalid critiques are naturally occurring false-flaw identifications where the critique model incorrectly claimed an error on a correct answer. Real variation in reasoning quality, not just which answer letter appears.
I test four models from the Qwen3.5 family (0.8B, 2B, 4B, 9B) on 150 ARC-Challenge items (multiple-choice science reasoning). A single architecture family spanning 10× in parameters isolates scale from architecture. Thinking mode is disabled to isolate the base decision process.
Bigger models resist bad evidence better
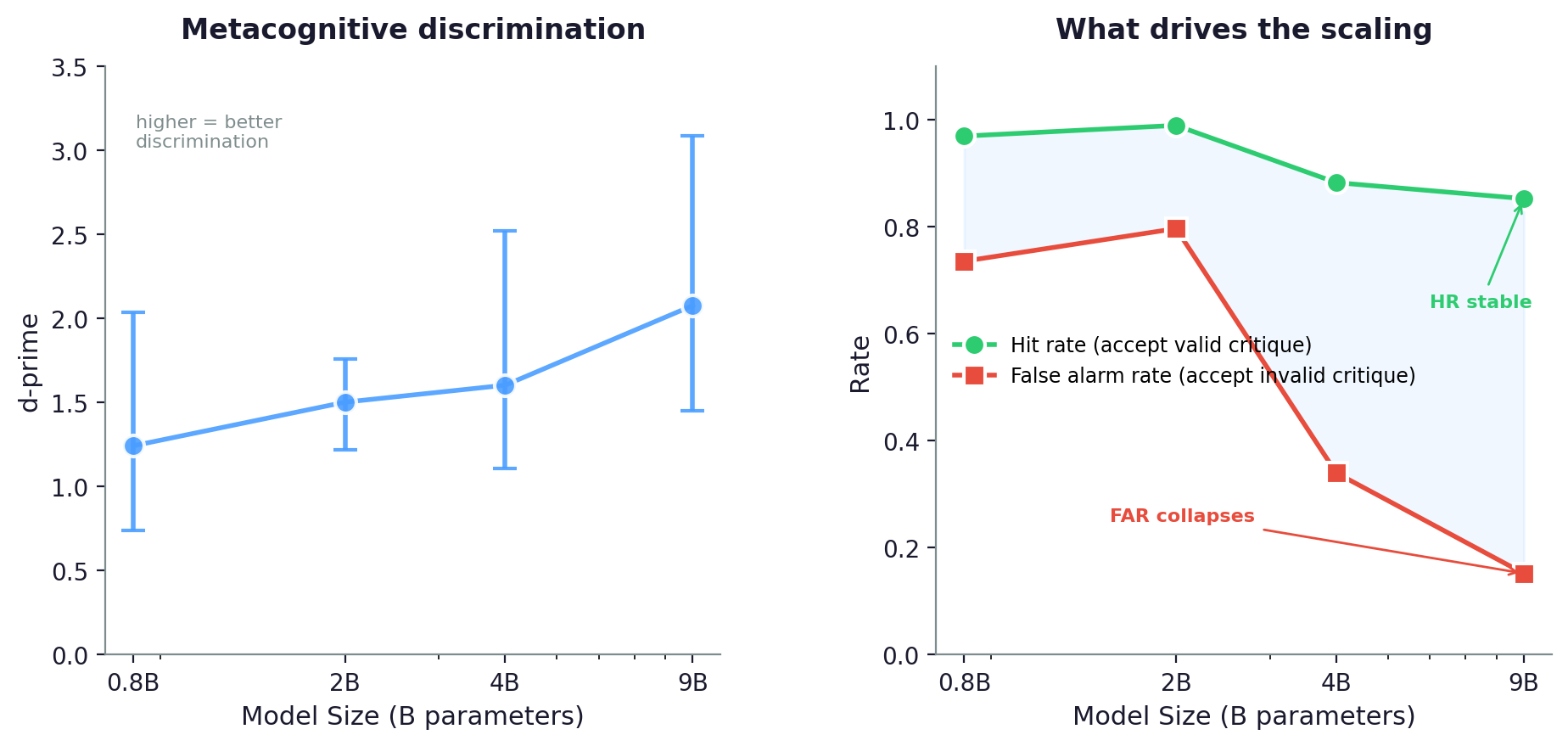
Left: d-prime (metacognitive discrimination) increases monotonically with model size. All 95% CIs exclude zero. Right: the mechanism is asymmetric. Hit rate (accepting valid critique) stays high across all sizes. False alarm rate (accepting invalid critique) collapses from 0.74 to 0.15. Larger models get better at resisting bad evidence, not at accepting good evidence.
The behavioral results are clear. d-prime increases monotonically from 0.8B to 9B:
| Model | Task Accuracy | d-prime | 95% CI | Hit Rate | False Alarm Rate | Criterion c |
|---|---|---|---|---|---|---|
| 0.8B | 46.0% | 1.243 | [0.74, 2.04] | 0.970 | 0.736 | -1.25 |
| 2B | 66.7% | 1.503 | [1.22, 1.76] | 0.990 | 0.797 | -1.58 |
| 4B | 80.7% | 1.604 | [1.11, 2.52] | 0.883 | 0.340 | -0.39 |
| 9B | 89.3% | 2.078 | [1.45, 3.09] | 0.853 | 0.152 | -0.01 |
All confidence intervals exclude zero. Every model shows real metacognitive discrimination, and the larger the model, the better it discriminates.
The mechanism is asymmetric. Hit rate stays high across all sizes (0.85–0.99). When the critique is valid and the model was wrong, it almost always revises, regardless of scale. What changes is the false alarm rate: 0.736 at 0.8B, 0.152 at 9B. The 0.8B model revises on 74% of invalid critiques. The 9B model revises on only 15%.
Metacognitive control scales because larger models get better at resisting bad evidence, not because they get better at accepting good evidence.
Criterion c moves from -1.25 (strong tendency to always revise) to -0.01 (no bias in either direction). The 9B model makes revision decisions based on critique quality alone. The 0.8B model’s tendency to always revise drowns out whatever discrimination ability it has.
The logprob gap
For each trial, I measure the mean token-level log-probability of the model’s initial answer, before any critique is presented. Items that the model ultimately revises on had lower initial logprobs (the model was less certain) than items it held firm on. This gap scales from -0.12 at 0.8B to -0.28 at 9B. The internal confidence signal becomes more connected to behavior at larger scales. The model’s pre-generation uncertainty increasingly predicts whether it will revise.
But only on science reasoning
The results above use ARC-Challenge — science reasoning with structured, falsifiable claims. A natural question: does the same scaling pattern hold on other task types?
I extended the benchmark to all eight datasets in the DS Critique Bank: ARC-Challenge, ARC-Easy, HellaSwag, CosmosQA, WinoGrande, PIQA, SocialIQa, and aNLI. These span science reasoning, commonsense inference, physical intuition, and social cognition. The total qualifying item pool is 969 questions with matched valid/invalid critiques.
On science reasoning (ARC-Challenge + ARC-Easy), the monotonic scaling pattern holds cleanly. On commonsense tasks, it does not. At N=600 with tight confidence intervals (mean CI width 0.77), the 4B model matches or exceeds 9B on commonsense items: d-prime 1.83 (4B) vs 1.64 (9B). This is not sampling noise. It reproduced across six independent configurations.
On science questions, the 9B model has strong enough domain knowledge to evaluate whether a critique’s reasoning is physically or chemically valid. On commonsense questions — “what pan to use for frying eggs,” “why someone walked around topless” — the difference between valid and invalid critique is harder to ground in formal knowledge. The 4B model’s commonsense representations are sufficient for this discrimination. More parameters do not help.
For the ARC-only results in the table above, the claim stands: d-prime scales monotonically with model size on science reasoning. The broader claim — that metacognitive control scales generally — requires qualification.
Where the model encodes this
The behavioral results show that metacognitive control scales. The mechanistic question is how. Following Moreno Cencerrado et al. (ICLR 2026 Workshop), I train difference-of-means linear probes on residual stream activations at the final prompt token, for every layer of every model, predicting two targets:
- Correctness: will the model answer this question correctly? (Replication of their method.)
- Revision appropriateness: will the model handle the subsequent critique correctly? (Novel construct.)
The first probe asks: does the model know its answer is right? The second asks: does the model know it will behave appropriately when challenged? Comparing them tests whether these are the same internal signal or distinct representations.
Both probes scale with model size:
| Model | Best Correctness AUROC | Best Appropriateness AUROC |
|---|---|---|
| 0.8B | 0.579 (layer 23/24, 96%) | 0.615 (layer 23/24, 96%) |
| 2B | 0.646 (layer 24/24, 100%) | 0.599 (layer 20/24, 83%) |
| 4B | 0.786 (layer 30/32, 94%) | 0.727 (layer 12/32, 38%) |
| 9B | 0.786 (layer 32/32, 100%) | 0.768 (layer 32/32, 100%) |
The 9B model encodes revision-appropriateness at 0.768 AUROC from pre-generation activations alone — before the critique is even presented. The probes peak at different layers, and the pattern changes with scale.
At 0.8B, both probes peak at the same late layer (23/24). At 2B, they begin to diverge (correctness at layer 24, appropriateness at layer 20). At 4B, they split sharply: correctness peaks at layer 30 (94% depth), while appropriateness peaks at layer 12 (38% depth). The model develops a separate, earlier representation for “how I will handle critique” that is distinct from “whether I know the answer.” At 9B, they reconverge at the final layer.
Confidence and control start disconnected
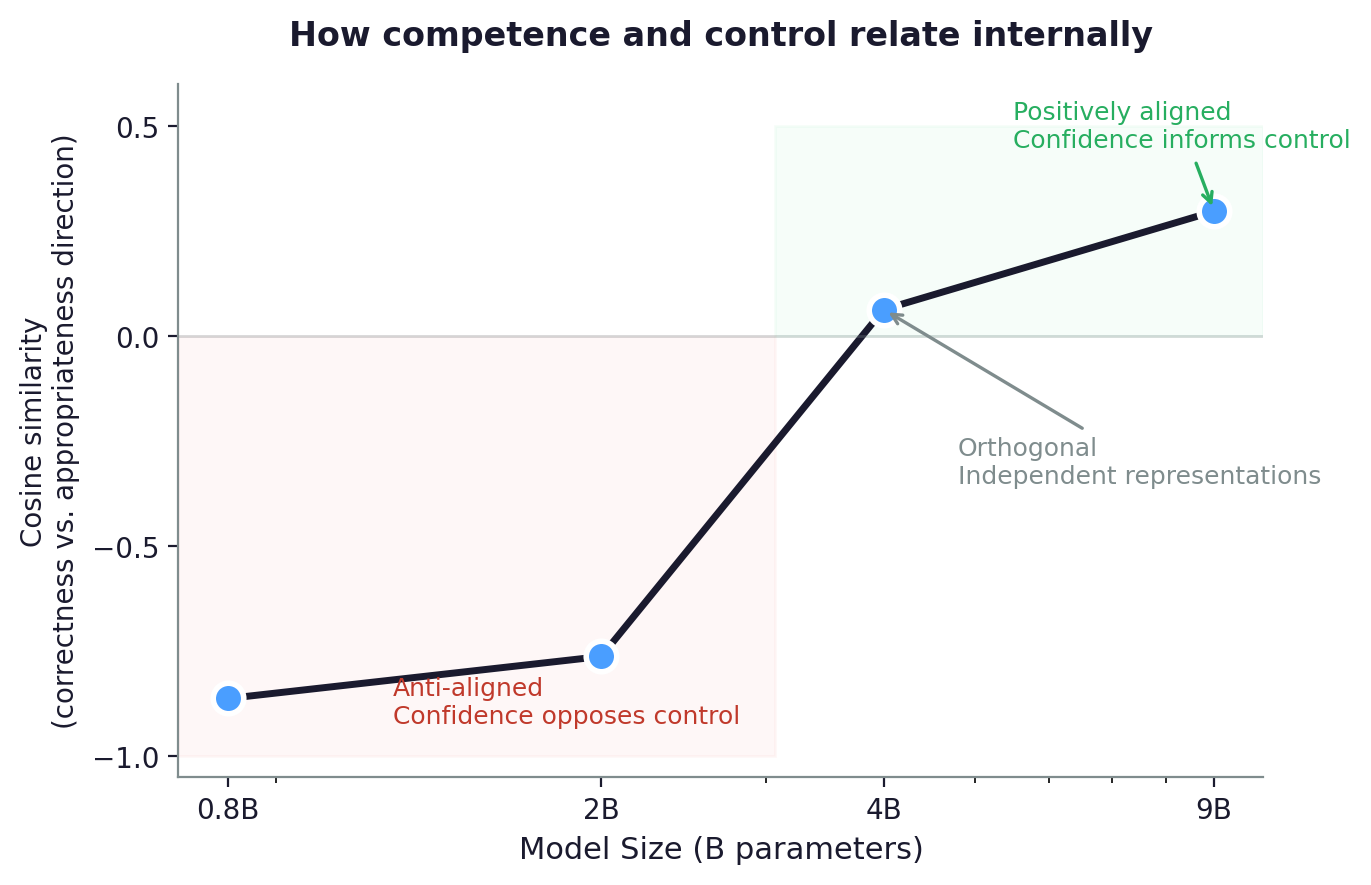
Cosine similarity between the “correctness” and “revision appropriateness” probe directions across model sizes. Three phases: anti-aligned (confidence opposes control), orthogonal (independent representations), positively aligned (confidence informs control).
Both representations exist and scale. But are they the same signal? I measure the cosine similarity between the “correctness” direction and the “appropriateness” direction at each model’s best layer. The result is a three-phase trajectory: at small scale, being confident about your answer makes you more likely to cave under pressure. At medium scale, confidence and control are completely independent. At large scale, they start to align.
| Model | Cosine similarity | What it means |
|---|---|---|
| 0.8B | -0.862 | Confidence opposes control |
| 2B | -0.740 to -0.785 | Still opposing |
| 4B | 0.064 | Fully independent |
| 9B | 0.298 | Starting to align |
The trajectory is: competence, then control, then integration. This parallels how metacognition develops in humans (Flavell, 1979) — raising the question of whether this sequence is inevitable in learning systems or an artifact of the training curriculum.
Balestriero et al. found that internal confidence is readable from the model’s representations but doesn’t actually drive its behavior — what they call the “Two Brains” analysis. That finding captures the 4B state: assessment and control are decoupled. What I show is that this decoupling is not permanent. It is a phase in a scaling trajectory that resolves at larger model sizes.
Recent work points in the same direction from the other end of the scale. A study across 19 frontier models from multiple labs found that confidence and capability were “almost completely uncorrelated” — self-certainty did not predict correctness, and the authors questioned whether confidence could serve as a reliable reward signal outside of math and code. The probe alignment trajectory here offers a mechanistic explanation. At the 4B scale, the correctness direction and the revision-appropriateness direction are literally perpendicular in activation space. The model has the confidence signal. It does not use it. If frontier models are still in this decoupled phase for many task types, confidence-based reward signals will systematically fail: the model’s self-certainty carries no information about whether it will handle a challenge correctly.
The domain-specificity finding sharpens this. On science reasoning, the alignment trajectory progresses toward integration (cosine similarity 0.30 at 9B). On commonsense tasks, the 4B/9B equivalence suggests the trajectory may stall. These data suggest confidence becomes a useful signal only where the model has structured domain knowledge to ground it in.
What this means
A model can know the answer without knowing how to defend it. The probes show that “I know my answer is right” and “I will handle critique correctly” are not the same internal signal — at least not until models reach sufficient scale. This decoupling means we can measure a capability that existing benchmarks miss entirely.
Accuracy alone is not enough. A model scoring 89% with d-prime 2.08 has a fundamentally different profile from one scoring 89% with d-prime 0.3. The first can tell good evidence from bad. The second cannot.
This only works where the model has real domain knowledge. The scaling trend holds on science reasoning but plateaus on commonsense tasks. Models need structured, verifiable knowledge to evaluate critique. On tasks where reasoning is informal and hard to falsify, more parameters do not improve discrimination. This constrains where confidence-based reward signals and self-play critique loops can be expected to work.
The critique quality is the benchmark. Template critiques (identical reasoning, only the answer letter varied) gave d-prime of 0.3. Domain-specific critiques from the DS Critique Bank gave 1.2 on the same items and model. The stimuli determine discriminatory power, not the number of items.
The broader point: this capability sits above task execution. It is not about whether the model can answer science questions. It is about whether the model can evaluate the quality of evidence presented to it and make the right call. Nelson and Narens (1990) call this the monitoring-to-control transition. The deployment question is the same: when an AI system receives conflicting information, can it tell which source to trust?
I tested small models. The question for frontier models is whether the scaling trend continues on science reasoning — and whether the commonsense ceiling breaks. If frontier models show the same 4B/9B equivalence on commonsense tasks that these small models do, it would suggest that metacognitive control on informal reasoning is a fundamentally harder problem than on structured domains.
Limitations
N is constrained at the extremes, and item sampling introduces variance. The 9B model answers 89% of questions correctly, leaving only 16 items in the “model incorrect” cell. The hit rate (0.853) is estimated from 16 trials. In follow-up experiments with N=200 random samples from the full 969-item pool, seed-to-seed variance on d-prime spread was approximately 0.53 — nearly the magnitude of the effect itself. The ARC-only results reported here are stable (deterministic item set), but extending to mixed-domain benchmarks requires substantially larger N or fixed item sets to produce reliable measurements.
Single model family. All four models are Qwen3.5. The probe direction alignment trajectory (anti-aligned → orthogonal → positive) may not generalize to other architectures or training procedures.
Domain coverage. The main scaling results use ARC-Challenge (science reasoning). The domain-specificity analysis extends to eight datasets but uses the same critique construction throughout. Different task types may need different critique designs to produce maximally discriminating stimuli. The commonsense ceiling could reflect limitations of the critique stimuli rather than a genuine capability plateau, though the consistency of the 4B/9B equivalence across six independent configurations argues against this.
Thinking mode disabled. Qwen3.5 models generate extended chain-of-thought by default. I disable this (injecting </think> immediately) to isolate the base decision process. With thinking enabled, metacognitive control may improve, and the relevant internal representations may shift. The interaction between explicit reasoning chains and implicit metacognitive representations is an open question.
No system prompt. System prompt moves d-prime by up to 0.8 points at 0.8B scale. The results here use no system prompt to establish a standardized baseline.
Probe methodology. The difference-of-means probe is intentionally simple, following Moreno Cencerrado et al. A non-linear classifier might achieve higher AUROC but would weaken the Linear Representation Hypothesis claim. Cosine similarity is computed at different layers for different models, which complicates direct comparison.
References
- Burnell, R., Yamamori, Y., Firat, O., et al. (2026). Measuring Progress Toward AGI: A Cognitive Framework. Google DeepMind.
- Fleming, S. M., & Lau, H. C. (2014). How to measure metacognition. Frontiers in Human Neuroscience.
- Nelson, T. O., & Narens, L. (1990). Metamemory: A theoretical framework and new findings. Psychology of Learning and Motivation.
- Moreno Cencerrado, I. V., et al. (2026). No Answer Needed: Predicting LLM Answer Accuracy from Question-Only Linear Probes. ICLR 2026 Workshop.
- Balestriero, R., et al. (2025). Confidence is Not Competence. ICLR 2026.
- Kumaran, D., Fleming, S. M., et al. (2025). How Overconfidence in Initial Choices and Underconfidence Under Criticism Modulate Change of Mind in LLMs. DeepMind.
- Saadat, M. & Nemzer, S. (2026). Certainty Robustness: Evaluating LLM Stability Under Self-Challenging Prompts.
- Hong, S., et al. (2025). Measuring Sycophancy of Language Models in Multi-turn Dialogues. Findings of EMNLP 2025.
- Gu, J., et al. (2024). DS Critique Bank. ACL 2024.
- Kirichenko, P., et al. (2025). AbstentionBench: Reasoning LLMs Fail on Unanswerable Questions.
- Wang, G., et al. (2025). Decoupling Metacognition from Cognition: A Framework for Quantifying Metacognitive Ability in LLMs. AAAI 2025.