Rethinking Evaluation for Agents That Never Stop Learning
Working note on research in progress. First drafted 2026-01-13, last revised 2026-06-04.
Eval cost is already becoming its own bottleneck. The Holistic Agent Leaderboard spent about $40,000 to run 21,730 agent rollouts across 9 models and 9 benchmarks, and a single GAIA run on a frontier model can cost $2,829 before caching. (AI evals are becoming the new compute bottleneck)
Test-time compute changes the unit of intelligence. A frontier model becomes model weights + inference-time search + tools + verifiers + memory + environment feedback.
The result depends on the model, the harness, the tools, the memory, the scaffold, the token budget, and the amount of time the agent is allowed to keep working. Change the harness and you can change the score. Terminal-Bench makes this visible. It evaluates agents inside a terminal harness that orchestrates them, spins up Docker environments, logs actions, and verifies container state. (Introducing Terminal-Bench) Stanford’s Meta-Harness shows the same model can improve substantially when the scaffold gathers environment state before the agent loop starts. (Meta-Harness artifact)
Test-time compute inverts the problem. A single Pass@K score hides the cost curve behind the result. AISI and Irregular found that recent frontier models can use 10-50x larger token budgets on cyber tasks than typical eval setups allow, with some hard tasks solved only when the budget increased from 10M to 50M tokens. (AISI inference scaling in cyber tasks) NCSC summarizes the same direction of travel for cyber. More processing time reliably improves results, and current evaluations may understate what models can do. (Why cyber defenders need to be ready for frontier AI)
I do not doubt that benchmarks will survive. They will. The question is what sits above them.
What Makes an Evaluation Online?
An evaluation is online when it updates with the agent.Online means the evaluation changes as new data arrives, rather than being fixed after construction. In ML, online systems update from a stream. Here, the stream is agent work, traces, outcomes, edits, and environment feedback.
From first principles, an eval defines the task distribution, the success condition, and the measurement unit. For agents, all three move.
| Axis | Static benchmark | Online evaluation |
|---|---|---|
| Task distribution | Fixed item bank | Stream of production traces, mutations, composed variants |
| Success condition | Author-defined, frozen | Verifier that hardens as shortcuts surface |
| Measurement unit | Pass@K on the bank | Frontier map plus an anchor set |
| Comparability | Same items over time | Anchor layer holds scale; frontier layer is policy-conditioned |
| Failure mode | Memorization, distribution mismatch | Frontier drift, verifier exploit, rubric Goodhart |
An online eval has to handle every row at once.
The task distribution comes from the stream of real work the agent is attempting, and it moves as the agent improves.
Production traces are the raw material, not the benchmark. A trace shows the user intent, environment, tools, retrieved context, explored branches, failure points, human corrections, and final artifact. Those traces contain the shape of the work. The eval extracts that structure and turns it into new tasks.
Open-world evaluation matters here.Open-world evaluations are long-horizon, messy, real-world tasks assessed through qualitative analysis of small samples. Kapoor et al. frame them as a complement to benchmark-scale automation for measuring frontier capabilities. (Open-world evaluations for measuring frontier AI capabilities) Benchmark-based evaluation can both overstate and understate real-world capability because benchmarks favor tasks that are precisely specified, automatically graded, short-horizon, and cheap to run. Open-world evaluations attack the problem from the other side. They use long-horizon, messy, real-world tasks as frontier probes.
Online evaluations measure the moving boundary of what a system can do. Given the traces of real work, what task would reveal the next capability boundary?
The eval then generates controlled variants near that boundary. Change the environment. Shift the constraints. Require another tool. Add a verification step. Remove a shortcut. Keep the underlying capability fixed, but make the exact task new.
The point is to discover capability. A failure trace can reveal a weakness. A near-success trace is just as valuable. It shows where the agent is close and where the eval samples next.
That requires a loop running trace ingestion, task generation, rollout, verification, and frontier update. The teacher is the part of the loop that decides where to sample next.
This turns evaluation from a score into a frontier map.
Defining The Loop
The loop has four moving parts.
Policy
The policy is the agent being evaluated. It learns through weights, memory, retrieved context, tool use, scaffolds, and prior attempts. Even when the base model is frozen, the deployed system changes.
Teacher
The teacher is an LLM that decides where to sample next. It reads traces and frontier results, then proposes new tasks near the agent’s current boundary. It does not only generate harder tasks. It generates tasks close enough to reveal movement.
Verifier
The verifier decides whether the task is grounded. It checks whether the answer can be scored, whether the tool trace supports the result, and whether the task admits shortcuts. As the policy improves, the verifier hardens.
Rubric
The rubric decides what progress counts. It separates shallow completion from robust success. It tracks whether the agent verified, decomposed, recovered, used tools correctly, and produced an artifact that would hold up in the real setting.
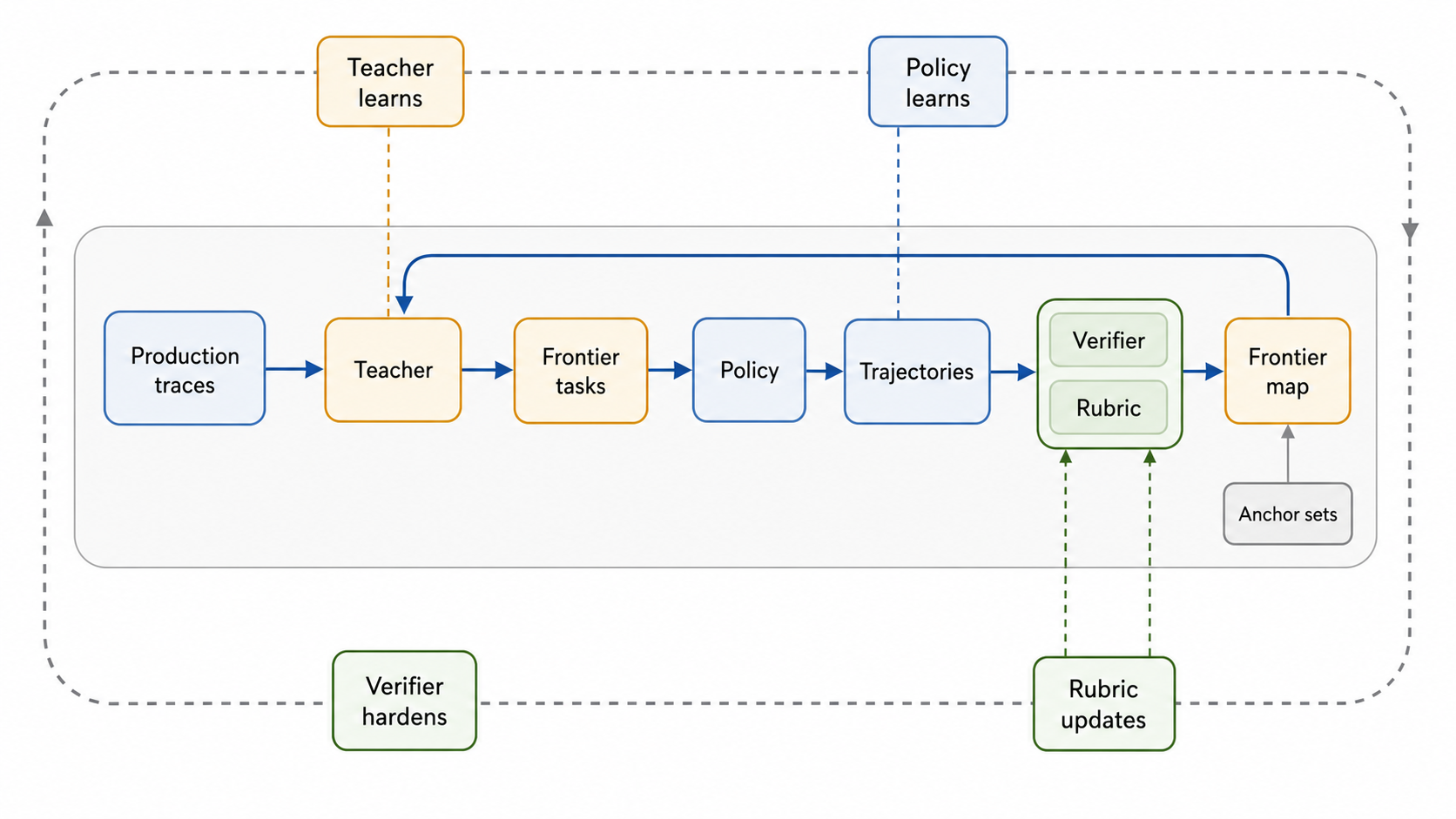
The loop’s four parts cycle through trace ingestion, task generation, rollout, verification, and frontier update.
Each part evolves on a different signal. The policy updates from experience. The teacher updates from the frontier map. The verifier updates from exploits and ambiguity. The rubric updates from the gap between measured success and real usefulness.
This creates two loops. The inner loop runs the eval. The outer loop updates the eval system itself.
Production traces seed the task distribution. The teacher turns traces into frontier tasks. The policy attempts them. The verifier checks whether the outcome is real. The rubric scores the behavior. The result updates the frontier map, and the next sampling decision starts from there.
That outer loop is a measurement system that improves as the agent improves.
Measurement Integrity
The core measurement problem is identifiability.
Once the task distribution changes, a score can move for two reasons. The policy improved, or the eval changed. Online evaluation only works if it can separate those effects.
Fluid Benchmarking is the closest static analogue. It adapts item selection to the model being measured, but uses item response theory to keep items on a shared ability scale. For agents, the same principle has to extend beyond item choice to tasks, environments, tools, scaffolds, verifiers, budgets, and time.
The frontier layer moves. It samples from traces, near-successes, human edits, and verifier exploits to find tasks that are informative for the current policy.
The anchor layer stays comparable. It replays fixed slices, fixed budgets, and calibrated task families to preserve scale.
If the frontier layer moves alone, the eval becomes exploration without a ruler. If the anchor layer dominates, the eval becomes a stale leaderboard.
The online eval has to estimate both at once. Where is the frontier now, and how much of that movement is real capability gain?
Where The Loop Overlaps With Training
Online evaluation borrows the shape of a post-training loop. A teacher proposes, a verifier admits, and an async rollout produces evidence. The difference is the gradient. In post-training systems like DORA, PrefixRL, and multi-teacher on-policy distillation, that evidence updates the policy. Here it updates the measurement. The trajectories the eval produces become training data for the next round when the team is ready. Increased inference compute spent on the eval is not lost.
A Small Version Of The Loop
ShoppingBench is a real-world, intent-grounded shopping benchmark for LLM agents. It contains 3,310 user instructions over a sandbox of more than 2.5 million products, with tasks covering product finding, same-shop multi-product search, coupon and budget reasoning, and web-grounded shopping. (ShoppingBench paper) The code exposes the task as a tool environment: find_product, view_product_information, web_search, recommend_product, and terminate. (ShoppingBench code)
Shopping made sense as a proxy because it is grounded without being too large to inspect. A good shopping agent has to bind user intent to catalog state, inspect product details, reason over constraints, and produce a final recommendation that can be checked.
Production trajectories are the seed. The teacher reads observed rollouts, mutates near the boundary, and the verifier admits only tasks that stay grounded.
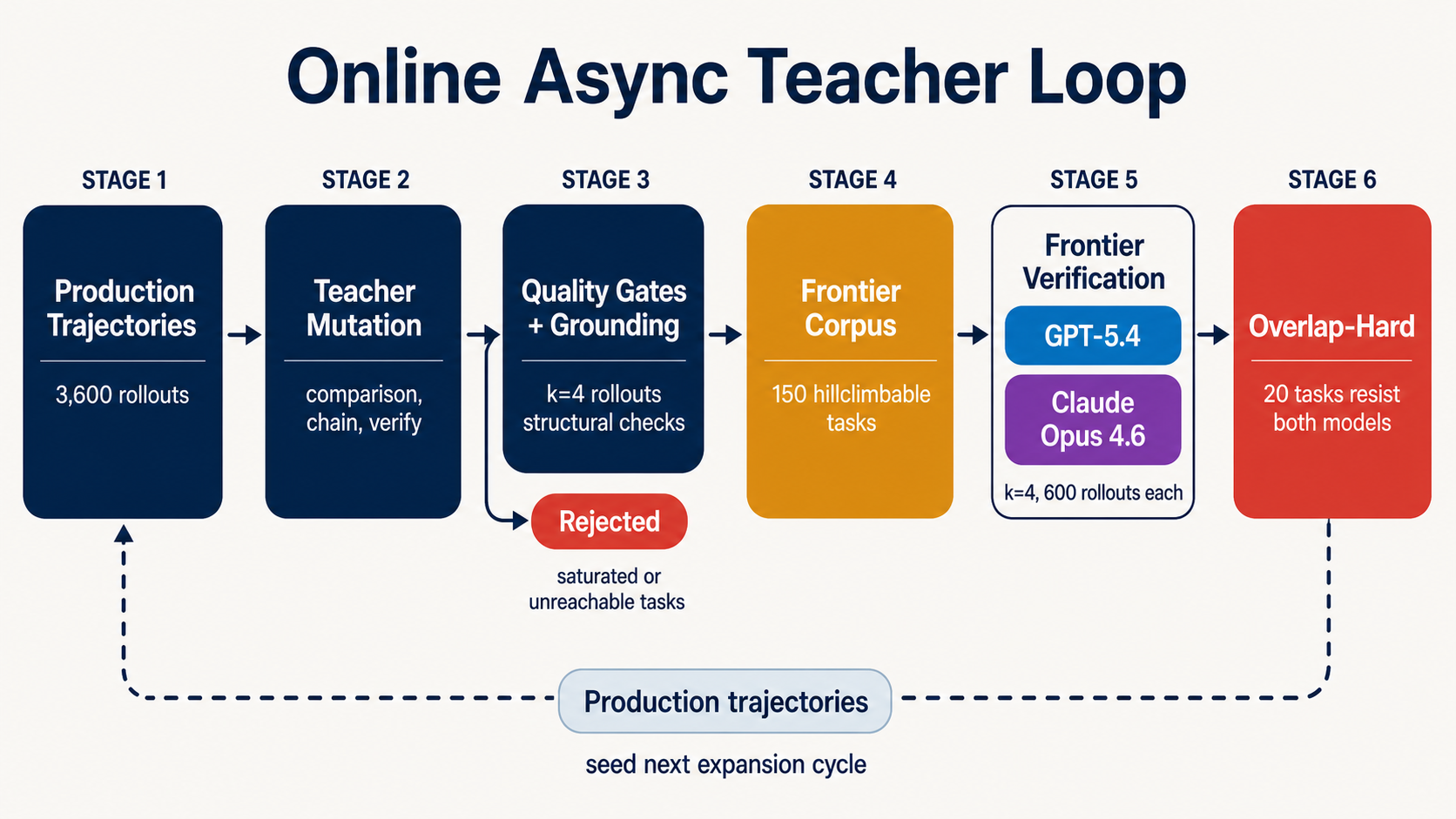
The async teacher loop instantiated on ShoppingBench. Production trajectories seed the next expansion cycle, and numbered stages match the seven-step procedure below.
The small version of the loop looked like this.
- Profile the policy on the current task set.
- Generate nearby tasks from the observed frontier.
- Run rollouts under a fixed harness and budget.
- Verify the outcome against the trace and rubric.
- Admit tasks that are grounded, scoreable, and hillclimbable.
- Audit the frontier corpus with stronger models.
- Feed the result back to the teacher.
In the first pass, the profiler re-ran 900 ShoppingBench tasks with Qwen3.5-35B-A3B at k=4, producing 3,600 trajectories. That gave the teacher a behavioral map rather than a static item bank. The online loop then generated 894 candidates, admitted 177 hillclimbable tasks, and retained a 150-task frontier corpus. (frontier dataset)
The useful signal was not “harder shopping tasks.” It was frontier structure.
Some tasks were saturated. Some were unreachable. The valuable tasks sat between those regions. The model could retrieve relevant products but failed when the task required an extra verification step, a same-shop constraint, voucher arithmetic, or comparison across inspected candidates.
The teacher converged on a single mutation family without being prompted to. Verification gates force the model to inspect product information before recommending. The ShoppingBench paper identifies view_product_information usage as the strongest single predictor of success across all four task splits (Wang et al., Figure 5). The teacher independently rediscovered the most discriminative behavior the paper itself names.
What The Proxy Reveals
The maintained frontier corpus exposed three properties that matter for online evals.
Frontier difficulty is model-relative. A task can be saturated for one policy, hillclimbable for another, and unreachable for a third. That makes fixed task difficulty the wrong abstraction. The eval needs a policy-conditioned frontier profile.
Composition over novelty. In ShoppingBench, the hard cases were not exotic shopping requests. They were ordinary requests with one extra constraint that changed the reasoning chain, like inspecting before recommending, binding multiple products to the same shop, applying a voucher threshold, or comparing verified candidates.
Verification is part of the task. Adding a product-information check changes what the model must do. It turns retrieval into grounded decision-making. That means the verifier is not just a judge after the rollout. It shapes the capability being measured.
A frontier-model audit on the 150-task corpus (k=4 each from GPT-5.4 and Claude Opus 4.6, 1,200 rollouts) confirmed the corpus was real. 55 tasks stayed hard for GPT-5.4, 24 for Opus, 20 hard on both, and 4 scored zero on both. The failure modes diverged. GPT-5.4 often failed before completing the chain (52.7% terminate rate on failed rollouts). Opus completed the chain but missed the final verification (98.5% terminate, 92.7% inspect). The 20-task overlap-hard subset becomes the canary. When a future model saturates it, the frontier has genuinely moved and the next expansion cycle starts.
The general lesson is that online evals do not only need a teacher that generates nearby tasks. They need a verifier and rubric that define the behavioral boundary worth sampling.
Where This Points
The next evaluation layer is not a larger benchmark. It is an online measurement system.
Benchmarks still matter as anchors, shared tasks, and public reference points. But deployed agents create a new evaluation stream. The hard part is turning that stream into tasks without losing the ruler.
What’s invariant. Whatever the implementation, an online eval has to do four things at once: pull task structure from production traces, harden verifiers as the policy finds shortcuts, evolve rubrics as measured success drifts from real usefulness, and hold an anchor set steady while the frontier layer moves.
What’s a design choice. Where the loop slots into deployment (between releases, continuously, or per-domain). Whether the teacher is one model or a population. Whether tasks are mutated, regenerated, or composed from primitives. How long the anchor set stays fixed. Whether the rubric is human-written, learned from edits, or both. None of these is implied by the principles above.
Every rollout, human edit, and verifier call adds to the evidence the loop is built on. The measurement sharpens as the corpus grows, and the same trajectories become training data when the team is ready. What this produces is not a Pass@K on a frozen benchmark. It is a maintained set of tasks that stay unsaturated as models improve.
So the question is not whether benchmarks are doomed. The question is what role they play inside an online eval loop.
My current answer is that benchmarks become the stable substrate. The frontier is maintained by the loop around them.
References
- Kapoor et al. Open-world evaluations for measuring frontier AI capabilities. cruxevals.com/open-world-evaluations.pdf
- AI evals are becoming the new compute bottleneck. Hugging Face blog. huggingface.co/blog/evaleval/eval-costs-bottleneck
- Introducing Terminal-Bench. tbench.ai/about
- Stanford IRIS Lab. Meta-Harness: 76.4% on Terminal-Bench 2.0. github.com/stanford-iris-lab/meta-harness-tbench2-artifact
- AI Security Institute. Evidence for inference scaling in AI cyber tasks. aisi.gov.uk
- NCSC. Why cyber defenders need to be ready for frontier AI. ncsc.gov.uk
- Fluid Benchmarking. arXiv:2509.11106. huggingface.co/papers/2509.11106
- ShoppingBench. arXiv:2508.04266. arxiv.org/html/2508.04266
- ShoppingBench code. github.com/yjwjy/ShoppingBench
- ShoppingBench frontier dataset. huggingface.co/datasets/Jarrodbarnes/oro-shoppingbench-frontier
- Hu et al. DORA: A Scalable Asynchronous Reinforcement Learning System for Language Model Training. arXiv:2604.26256. arxiv.org/abs/2604.26256
- Setlur et al. Reuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes. arXiv:2601.18795. arxiv.org/abs/2601.18795
- Xu. Multi-Teacher On-Policy Distillation: A New Post-Training Primitive. yumoxu.notion.site/multi-teacher-on-policy-distillation